Overview
Klera Machine Learning services enable systems to become accurate in predicting future events by providing out-of-the-box intelligence/ability to automatically learn from given datasets (training datasets) without any explicit programming or human intervention.
Prerequisites
Hardware Requirements:
Number of records per user: 50K Records/Rows
|
Parameter |
Specifications (Minimum Recommended) |
|
RAM |
5 GB |
|
CPU |
2 Cores or 4 Hyper threads |
|
Disk |
100 GB |
|
|
Software Requirements:
|
Parameter |
Specifications (Minimum Recommended) |
|
Operating System |
Windows Server 2012 R2 (64 Bit) |
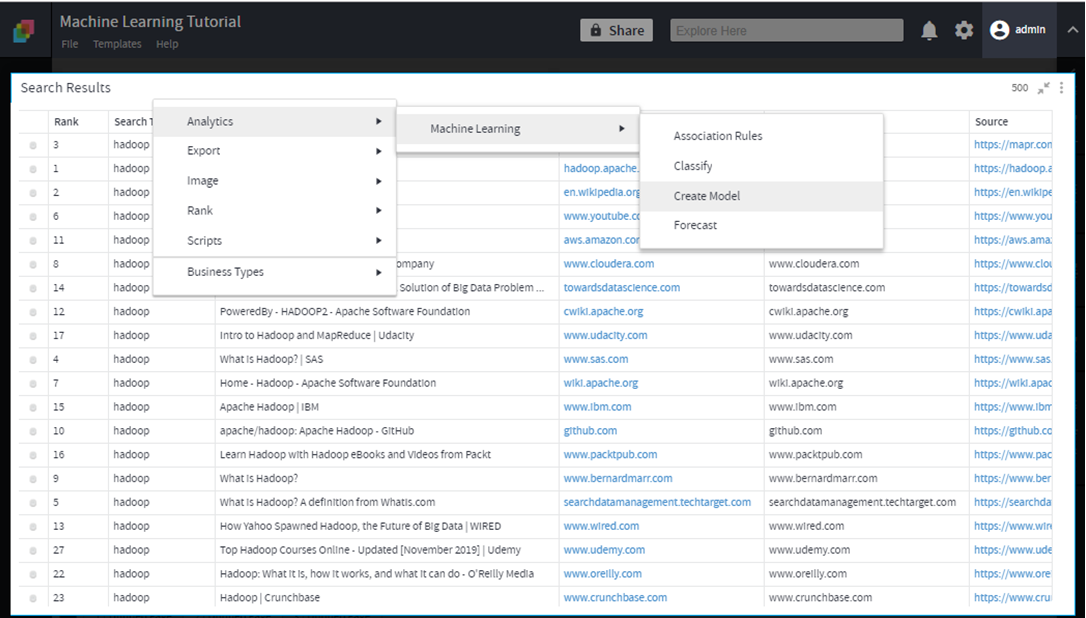
Features
- Create Model: Learns and Creates a model based on the input data set given.
- Classify: Classifies the data or Predicts events/class for the data based on the model created.
- Association Rules: Identifies frequent patterns in data.
- Forecast*: Forecasts time series data.
Note:
- *Forecast operation requires the Python module ‘fbprophet’ to be installed. Please install the package ‘fbprophet’ using “conda install”.
- Create model does not accept DATE/TIME/DATETIME columns as Feature columns or Class column.
- Models will be created in the following path:
"C:\AnalyticsModels\PythonCoreMLEngineModels".
Create Model
Operation is exposed on DST
On DST>Analytics>Machine Learning > Create Mode
Input Parameters
- Model Name:
Name of the model to be created.
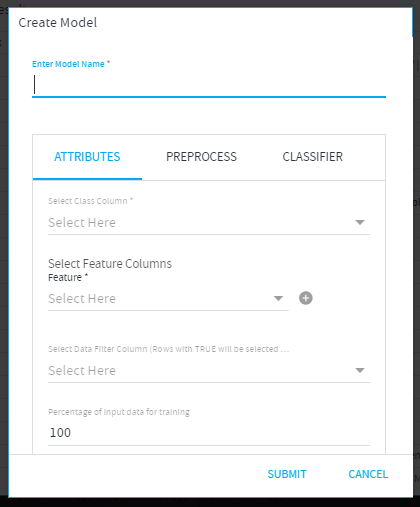
- Attributes: (Figure: 2b)
- Class Column: The column to be predicted.
- Feature Columns: The columns that will be used for predicting the Class.
- Filter Column: Rows that have a filter column value as TRUE will be selected for Create Model as input data. Only Boolean columns can be selected as Filter column.
- Percentage of Input Data to be used for Training: The percentage of data from your input DST/filtered input DST (as per the selection) that you enter in this field will be considered for creating the model. The remaining percentage of your data will be used for validating the model. For example, if you enter 100 percent then your entire data will be used for creating the model as well as validating it. If you enter 70 percent, then 70 percent of your data will be used for creating the model and 30 percent will be used for validating it.
- Preprocess:
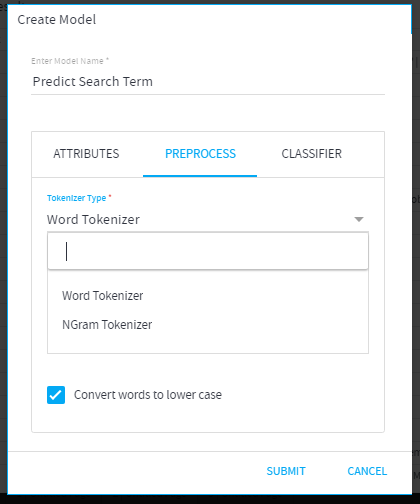
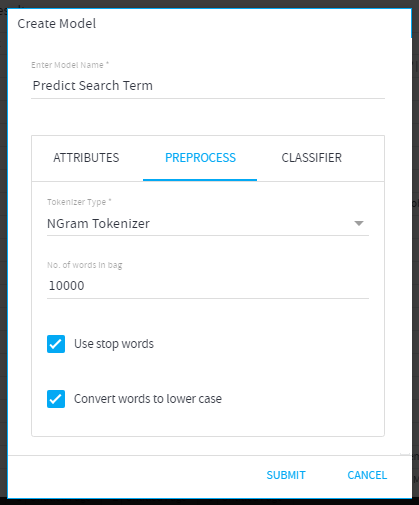
- Tokenizer Type: Type of the tokenizer to be applied on the DST:
I. NGram Tokenizer: This is used to break the text down into ngrams. (list of Tokens)
II. Word Tokenizer: It is used to break down the text into words. (list of Tokens) Note: An ngram is a contiguous sequence of n items from a given sample of text or speech. Note: An ngram is a contiguous sequence of n items from a given sample of text or speech.
Note: An ngram is a contiguous sequence of n items from a given sample of text or speech. - Number of words in the bag: Total number of words to be considered in the bag from input data. This is considered while building the DTM (Document Term Matrix) for creating the model.
-Minimum number of words=100
-Maximum number of words=10000 - Use Stop words: When selected, Stop words of the selected language will be dropped while forming the DTM.
- Convert words to lower case: By default, text is preprocessed in lower case. Uncheck this box, if you require upper casing.
- Classifier:
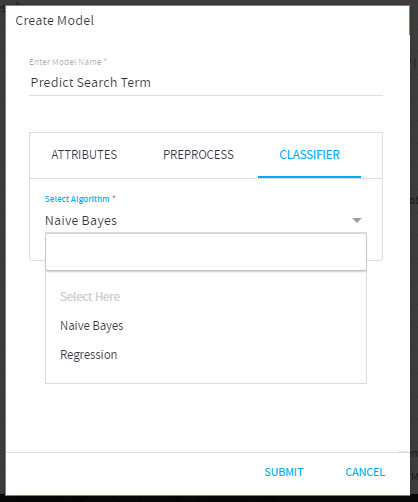
- Select Algorithm: Algorithm to Create model and Classify
I. Naïve Bayes: is used when the class column is non-numeric type.
II. Regression: is used when the class column is numeric type.
- Select Algorithm: Algorithm to Create model and Classify
Output Parameters
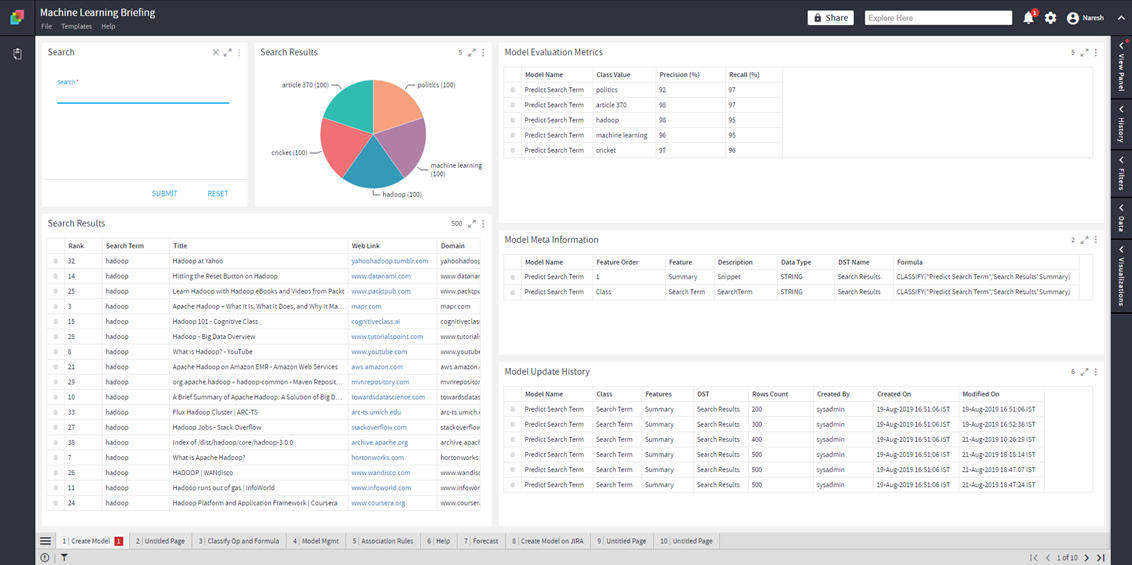
- Model Update History:
Shows the history of the model updates.
- Model Meta Information:
Gives the meta information of the model.
- Model Evaluation Metrics:
Provides the evaluation metrics of the model created.
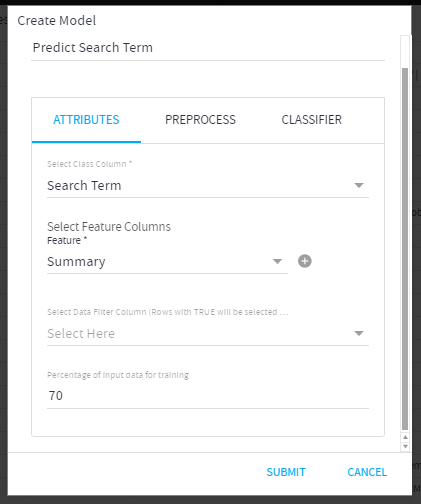
Let’s see how to Create Model:
In the example, we have a dataset of Google search results.
We are creating a model to predict the “Search term” based on the feature “Summary”.
- Model Name= Predict Search Term
- Class Column= Search Term
- Feature Columns= Summary
- Filter Column= Empty
- Percentage of Input Data for training= 70%
- Tokenizer Type= NGram Tokenizer
- Number of words in the Bag= 10000
- Use Stop Words= TRUE
- Convert Words to Lower Case= TRUE
- Select Algorithm= Naïve Bayes
On clicking Submit, model with name “Predict Search Term” would be created.
Classify
Enables the user to classify the input dataset, by applying a created model.
Operation would be exposed on DST
On DST>Analytics>Machine Learning > Classify
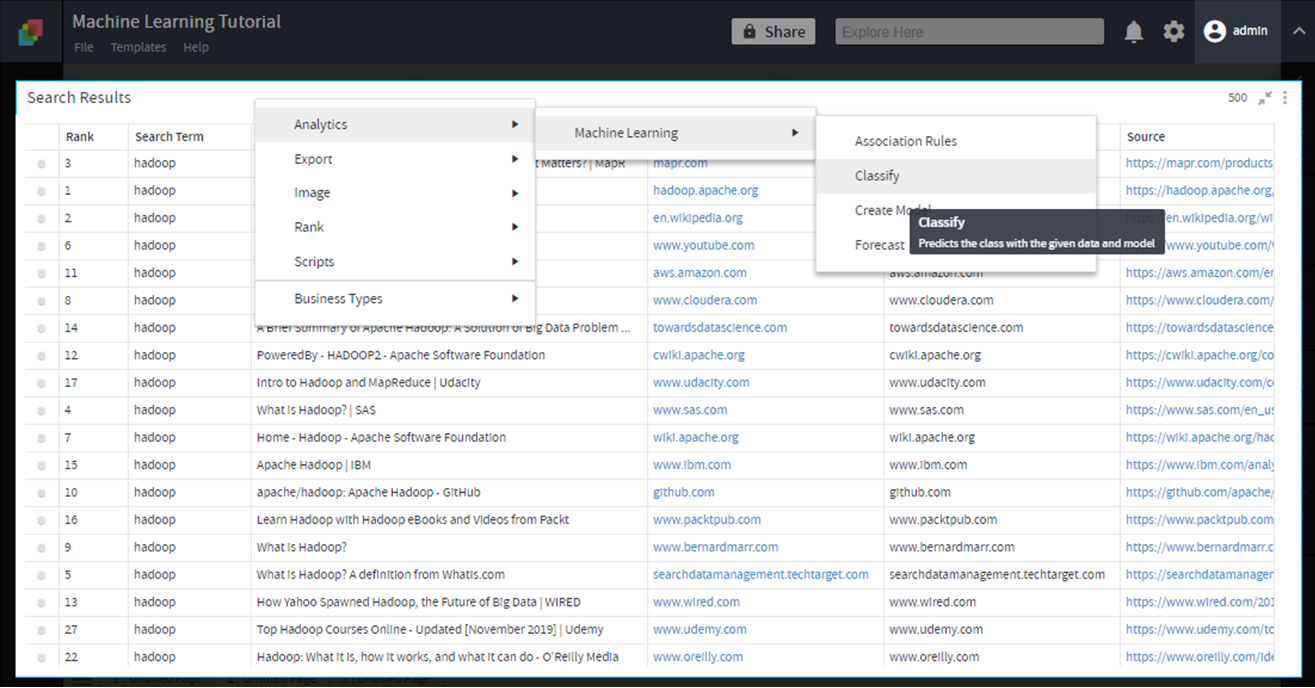
Input Parameters
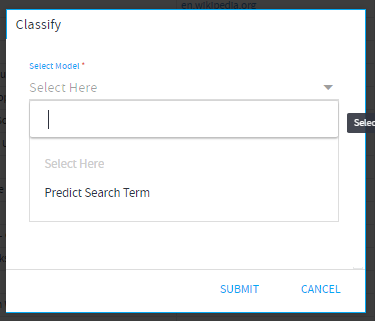
- Select Model:
Select the model to be applied from the model(s) created.
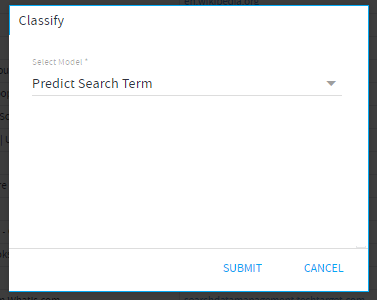
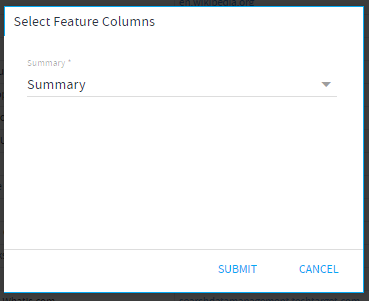
- Select Feature Columns:
Select the feature columns from the DST that are to be used.
Note: Columns, based on the data type used while creating the model, would be shown in the list.
Output Parameters
DST with Predicted Class based on the model selected
| Note: For each row in the input DST, |
- Most probable predicted class is given as input, in case of regression model created using Linear Regression.
- 3 most probable predicted classes are given as input, in case of classification model created using Naïve Bayes.
Let’s Classify using the model created:
Select Model= Predict Search Term
Select Feature Columns= Summary
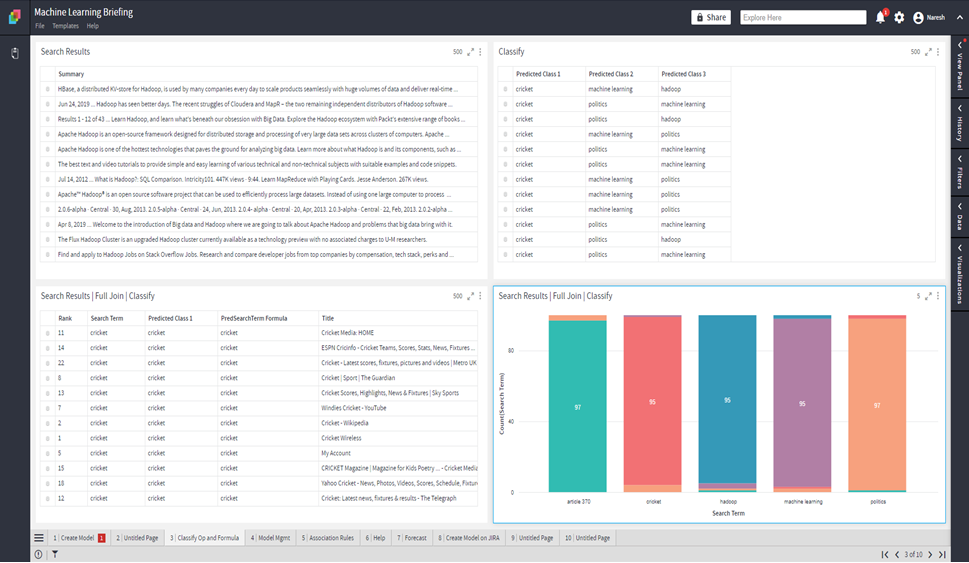
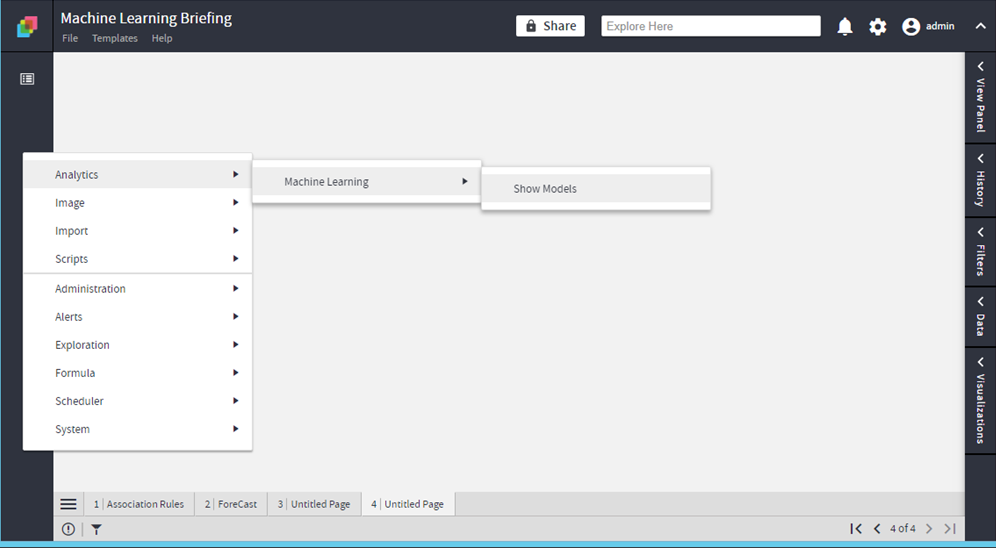
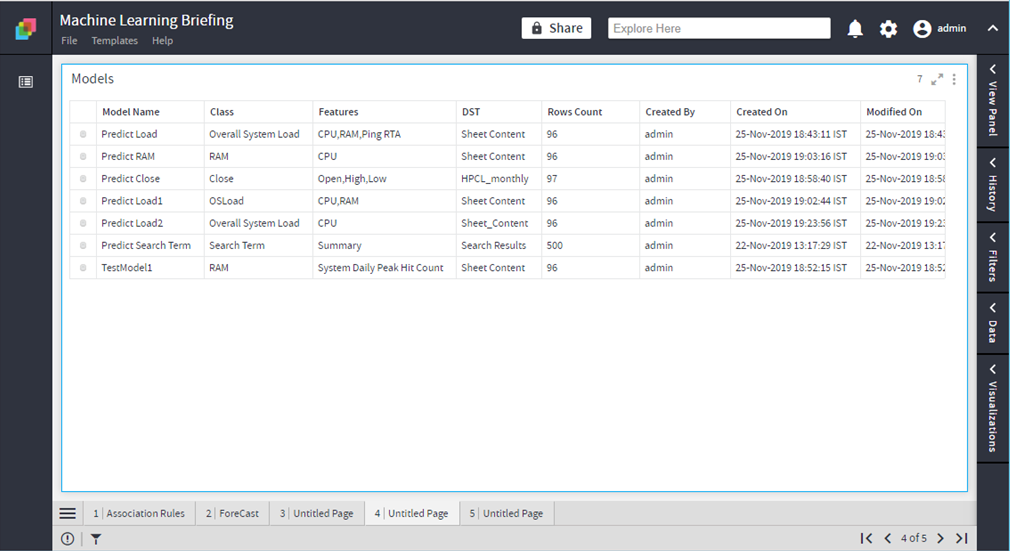
Show Models
Lists the models created by the user
The operation would be exposed on Floor:
Floor > Analytics >Machine Learning>Show Models
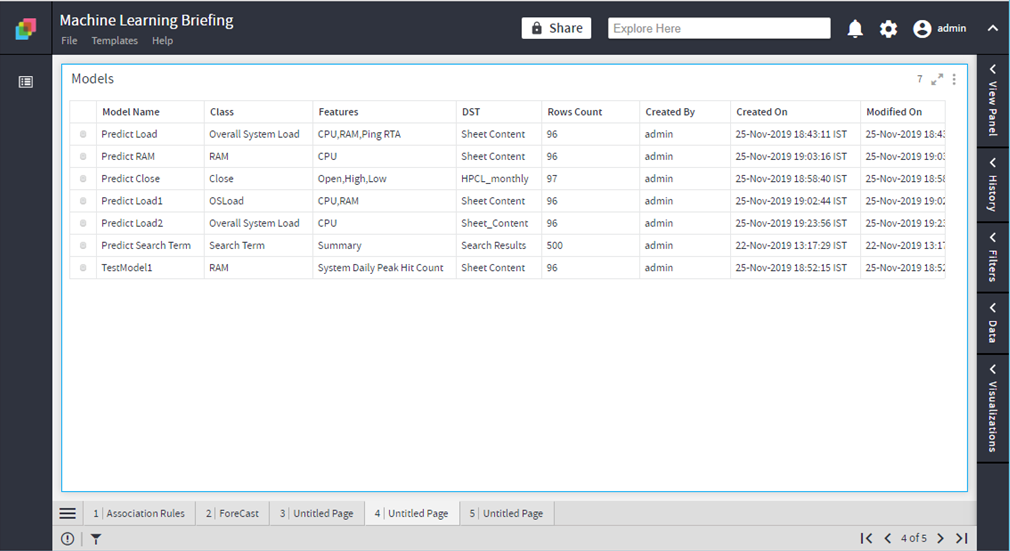
Delete Model
Deletes the selected model.
Model Details
Provides the model meta information.
Model History
Provides the model update History.
Rename Model
Renames the model.
|
|
Association Rules
Provides the frequent if->then patterns in the data provided.
Operation is exposed on DST:
On DST>Analytics>Machine Learning>Association Rules 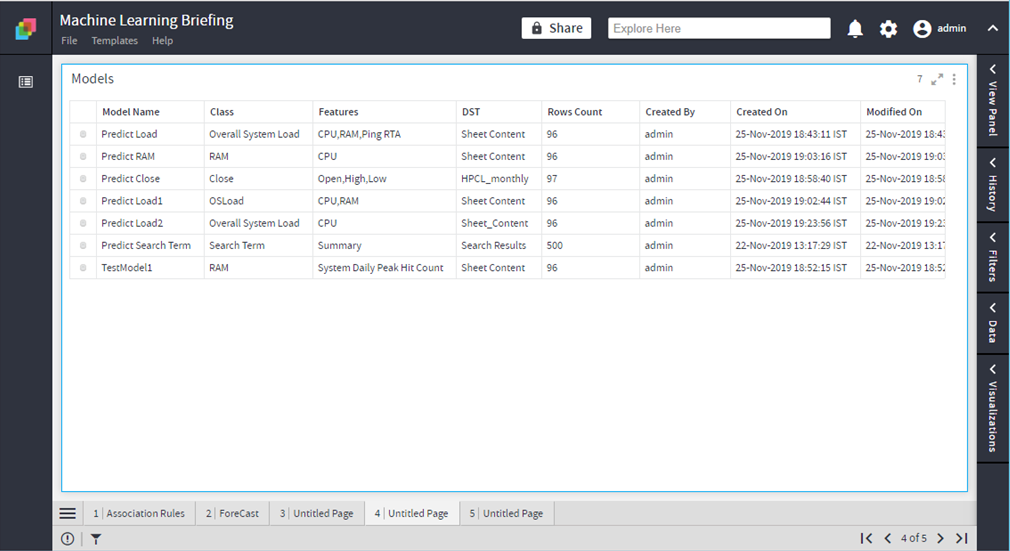
Input Parameters
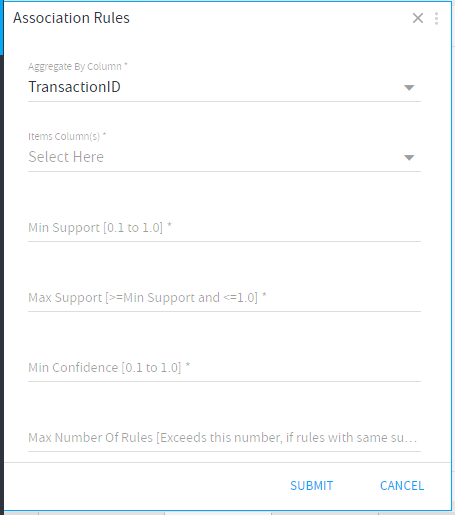
- Aggregate by Column
Column used to make a transaction (Set of items). - Items Column(s)
Columns used to prepare item sets. - Minimum Support* (0.1 to 1.0)
- Maximum Support* (>= Minimum support and <= 1.0)
*Support is an indication of how frequently the if-then relationship appears in the dataset. - Minimum Confidence* (0.1 to 1.0)
*Confidence is an indication of how often the if-then relationship is found to be true. - Maximum Number of Rules (N)
Maximum number of rules to be shown in the output.
Note: If multiple rules are generated with same support value, then number of rules will exceed this value.
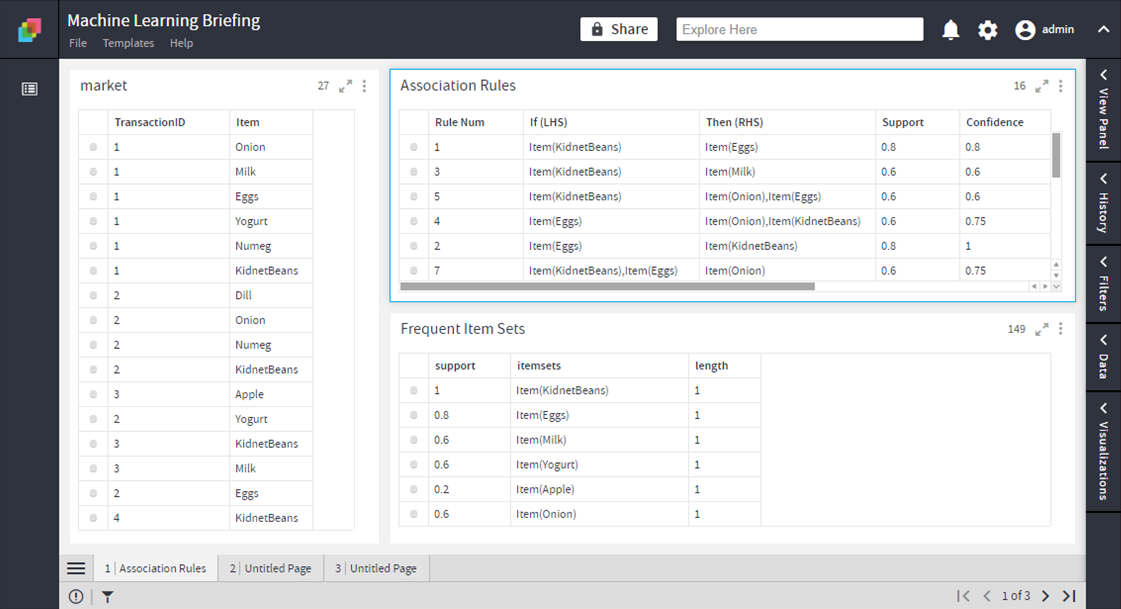
Output Parameters
- Association Rules
Rules as if-then sequence for items - Frequent Item Sets
Sets as frequently co-occurring items
For more information please follow the below links:
https://en.wikipedia.org/wiki/Association_rule_learning
https://www.saedsayad.com/association_rules.htm
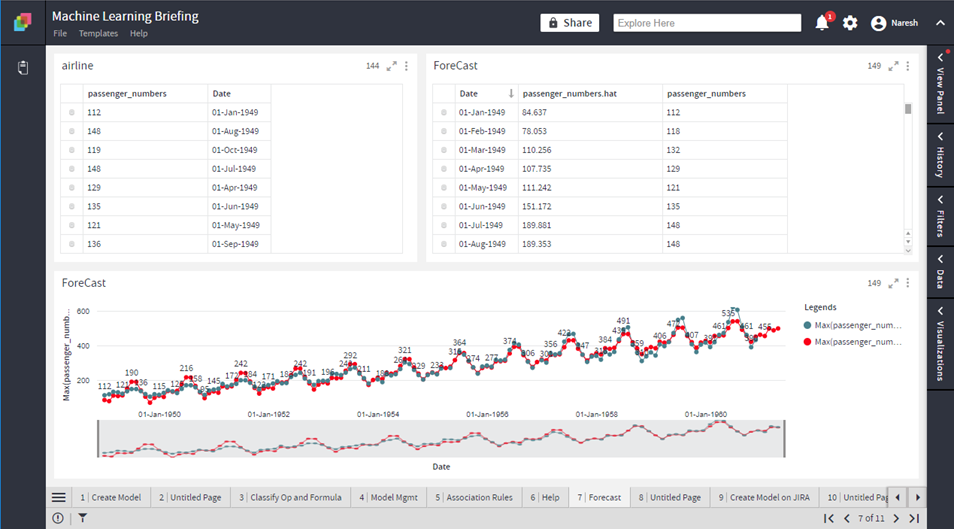
Forecast
Forecasts time series data
Note: Forecast requires the Python module ‘fbprophet ‘
Please install the package by using ‘conda install’ from command prompt
- Go to .\Anaconda3\Scripts folder
- Open command prompt with Administrator rights
- Run the below command **-
conda install -c conda-forge fbprophet
| **Note: This requires active internet connection |
The operation is exposed on DST
On DST>Analytics>Machine Learning>Forecast
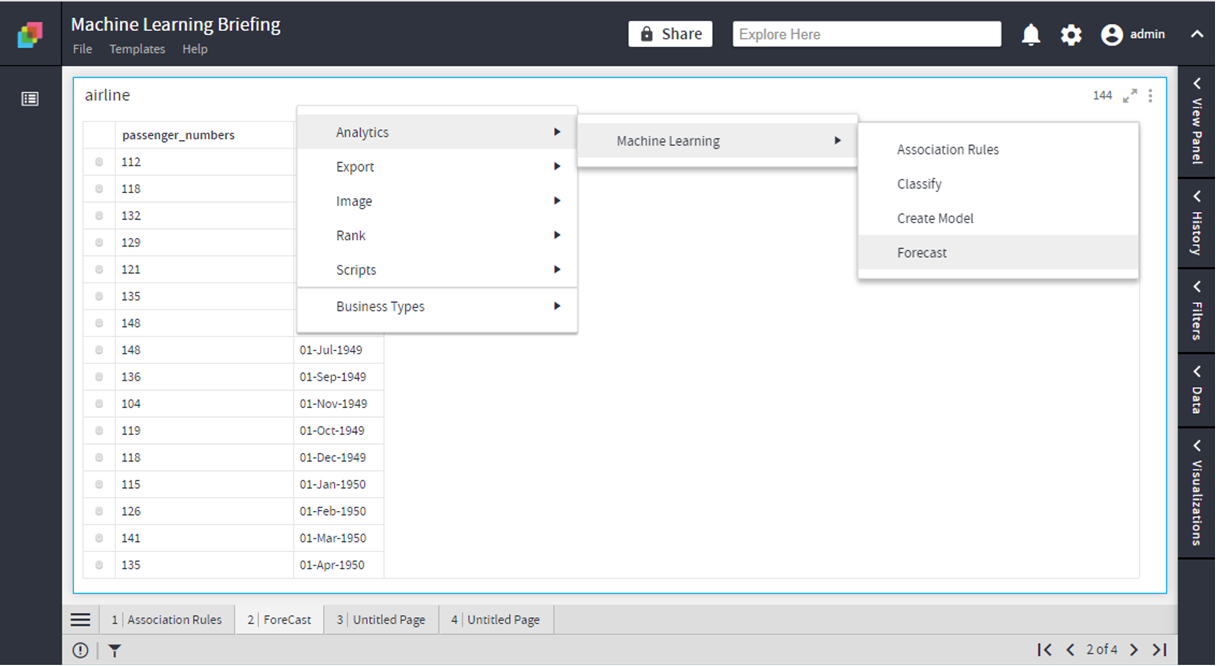
Input Parameters
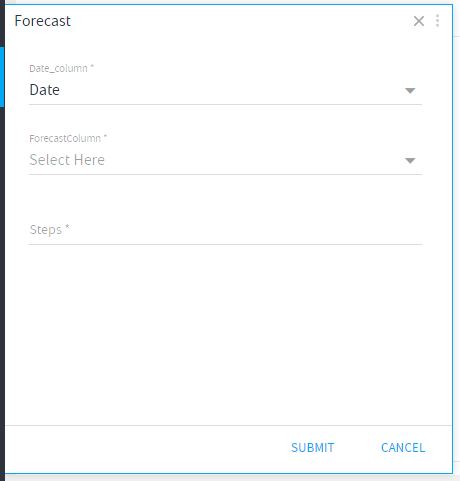
- Date_Column:
The dates in the column should be periodic. - ForecastColumn:
Column to be forecasted. - Steps:
Number of future steps to be forecasted.
Output Parameters
- Forecasted DST