You can derive powerful insights from datasets fetched from different tools by combining them on the basis of some common fields. Join and Union are well-known methods to combine rows of two datasets (called tables in SQL nomenclature).
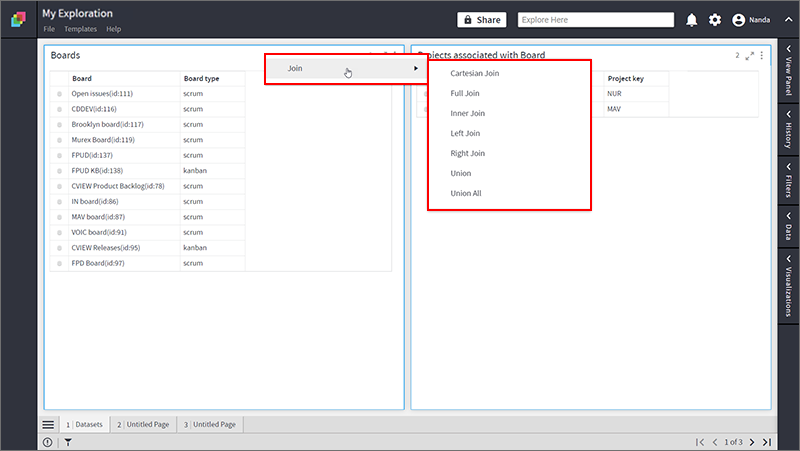
Klera provides the following types of Joins and Unions.
1. Inner Join
Inner Join results in a dataset containing rows from both the datasets, where the matching fields have the same value in both datasets.

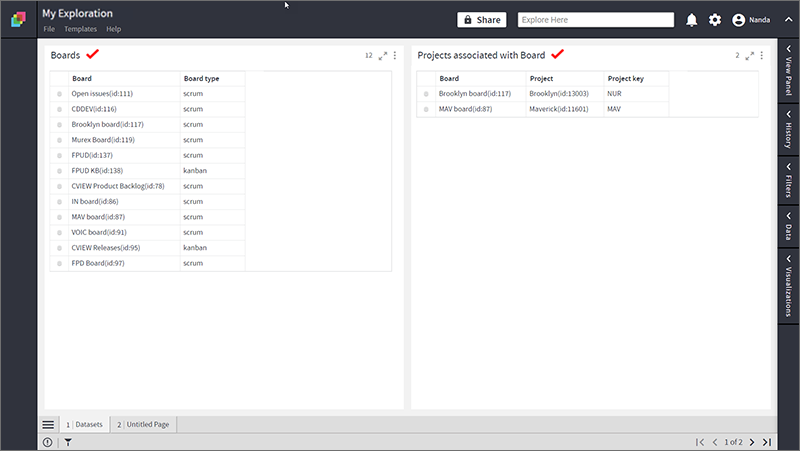
- Take two datasets; ‘Boards” and “Projects associated with Boards”.
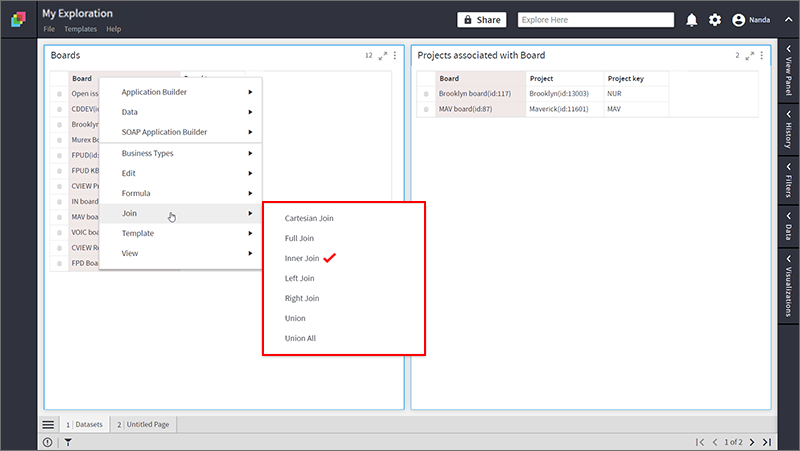
- Select the common “Board” columns in both the containers one-by-one by keeping the Ctrl key pressed.
- Right-click and select Join > Inner Join.
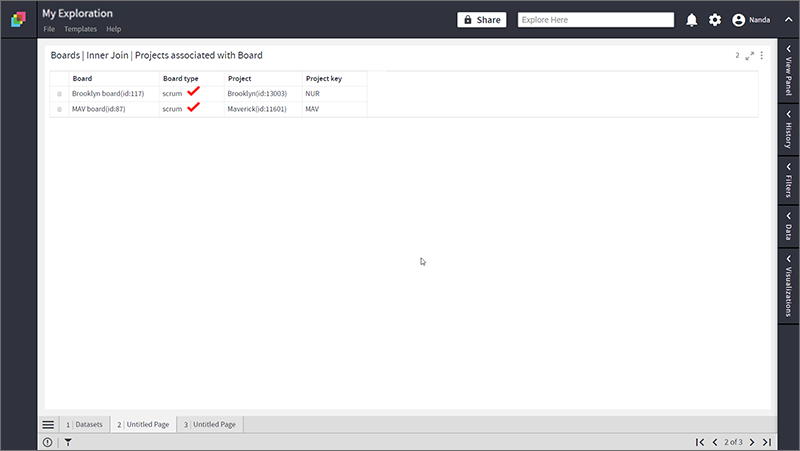
- Following is the resultant dataset for Inner Join containing rows where “Board” field was same.
2. Full Join
A Full Join results in the dataset containing all the rows of both the datasets, whether they are matched on the join columns or not. The rows for which there are no matches, the resultant dataset will contain NULL values.
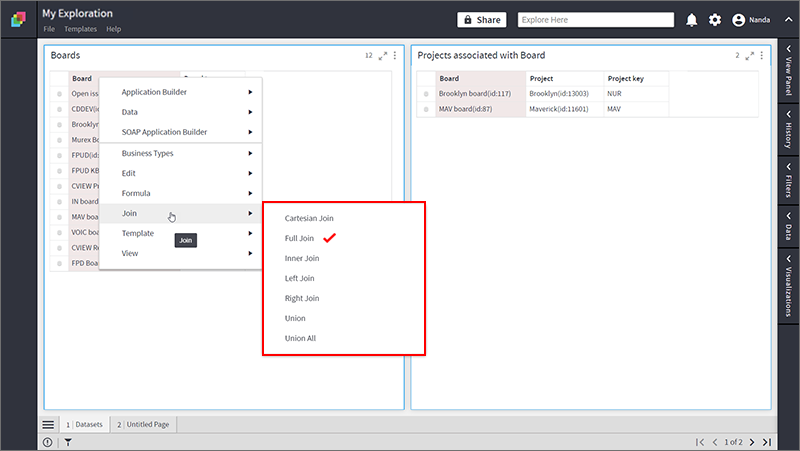
- Take two datasets; ‘Boards” and “Projects associated with Boards”.
- Select “Board” columns in both the datasets using the Ctrl key.
- Right-click and select Join > Full Join.
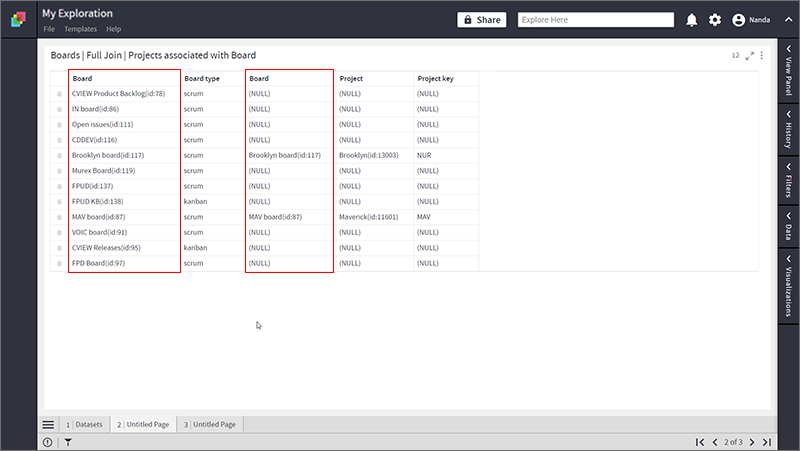
- Following is the resultant dataset for Full Join. Notice that it has two “Board” columns, one from each dataset. All matching and non-matching rows are included.
3. Cartesian Join
A Cartesian Join (also called Cross Join) creates the resultant dataset by combining (or crossing) each row of one dataset with every row of the other dataset.
- Take two datasets; ‘Boards” and “Projects associated with Boards”.
- Select “Board” columns in both the datasets using the Ctrl key.
- Right-click and select Join > Full Join.
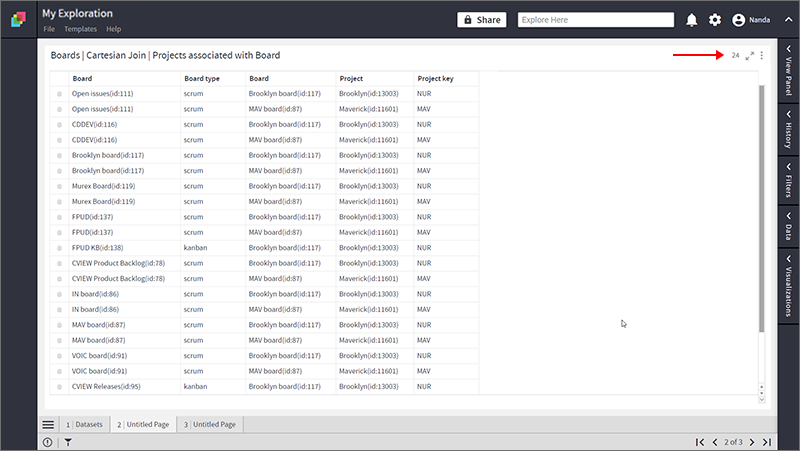
- Following is the result of Cartesian Join. Notice that the number of rows in the resultant dataset is 24, which is a cross product of the rows of datasets, Boards (12 Rows) and Projects ( 2 Rows) respectively.
4. Left Join
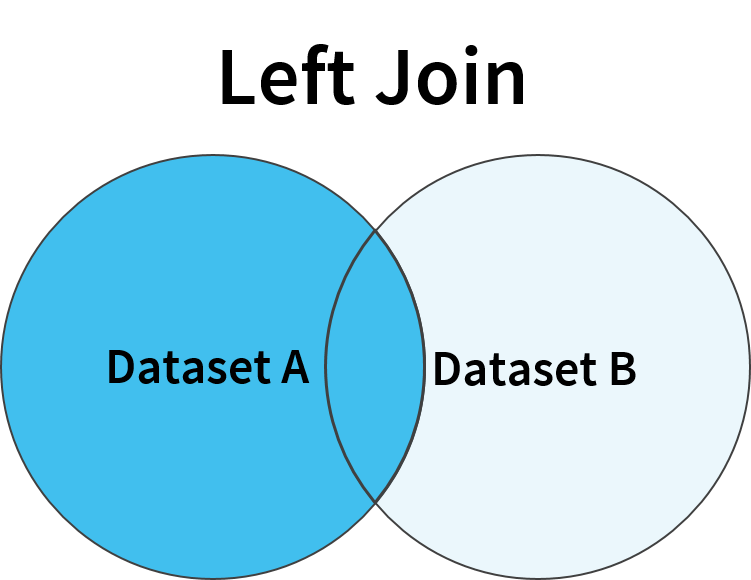
Left join results in a dataset containing all the rows from the left dataset even if there is no matching row in the right dataset. The rows for which there are no matches on the right side, the resultant columns will contain NULL values.
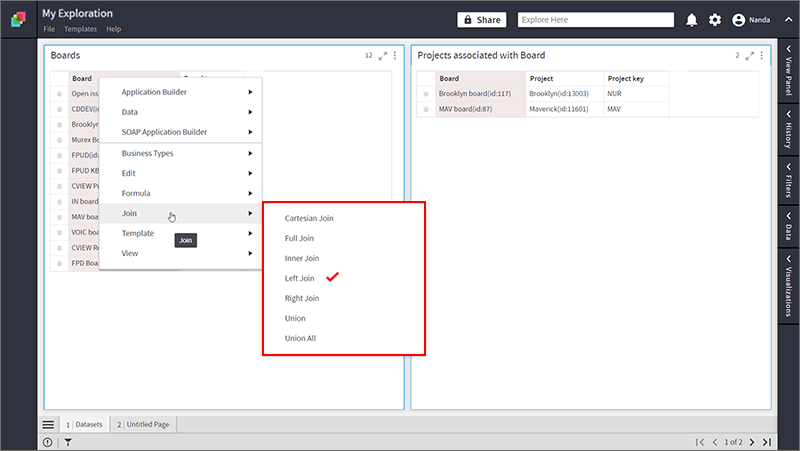
- Take two datasets; ‘Boards” and “Projects associated with Boards”.
- Select “Board” columns in both the datasets using the Ctrl key.
- Right-click and select Join > Left Join.
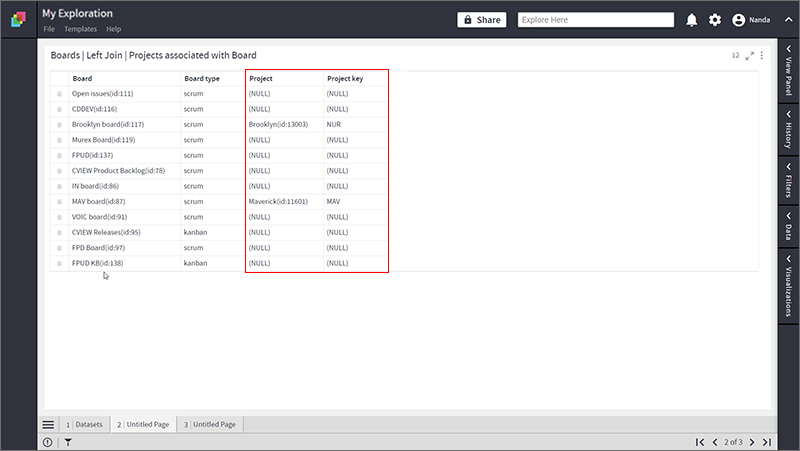
- Following is the resultant dataset for Left Join. Notice that rows in Left dataset have NULL values if there is no matching row in the right dataset.
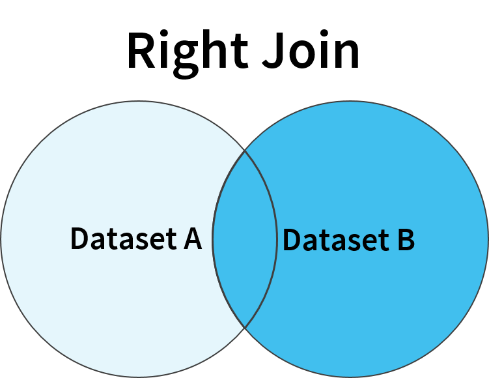
5. Right Join
Right Join results in a dataset containing all the rows of the right dataset even if there is no matching row in the left dataset. The rows for which there are no matches on the left side, the resultant columns will contain NULL values.
- Take two datasets; ‘Boards” and “Projects associated with Boards”.
- Select “Board” columns in both the datasets using the Ctrl key.
- To have “Boards” as the right dataset and Projects as the Left, Right-click on Projects container and select Join > Right Join
 Note: The Container on which you open the context menu is considered as the Left container and the other one the right container.
Note: The Container on which you open the context menu is considered as the Left container and the other one the right container.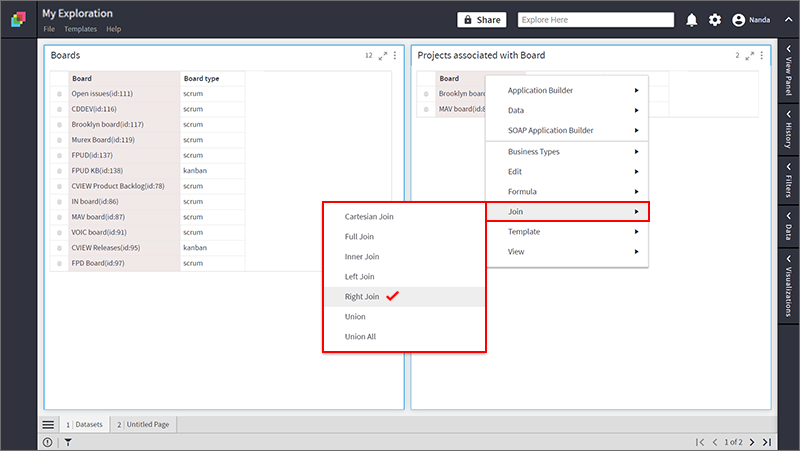
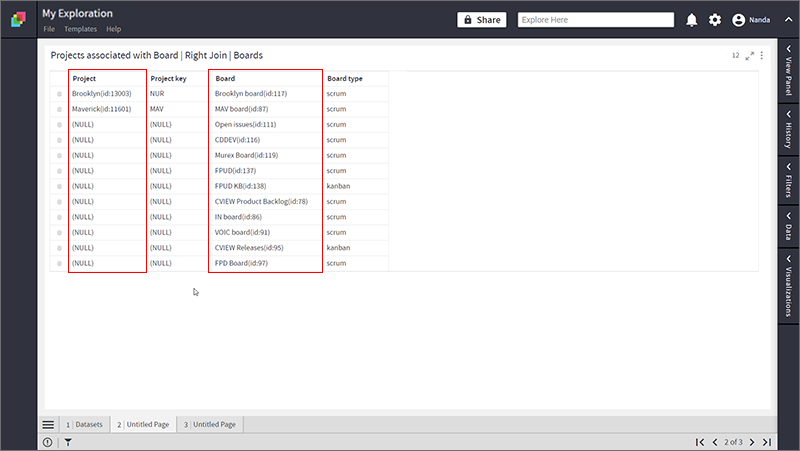
- Following is the resultant dataset for Right Join. Notice all the records from the right dataset (Boards) are retained. NULL values are populated for rows in Left dataset (Projects) where the join column didn’t match.
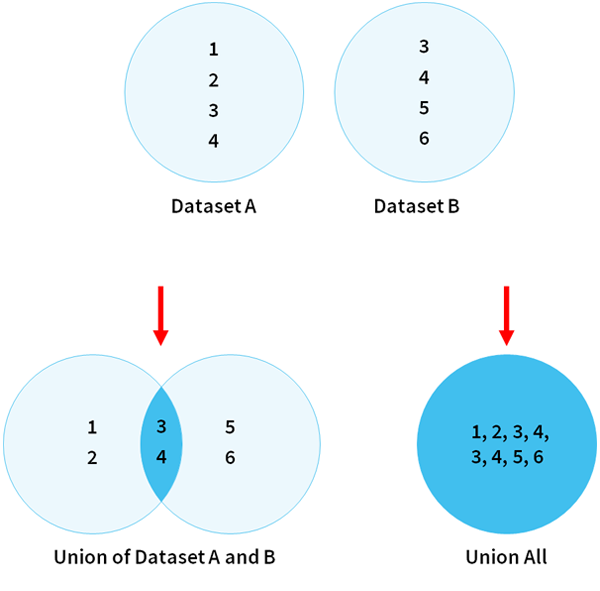
6. Union
Union is combining selected columns from two different datasets such that the resultant dataset will have the selected column only (unlike Joins where the resultant dataset contains All the columns, Join columns as well as the other columns of the datasets). The rows of both the containers are appended in the resultant container on the basis of the selected columns.
Union will work only when the selected columns from both the containers are of the same types. For e.g. If you select two numeric and three text columns in the first container then you need to select the same number and type of columns in the second container as well.
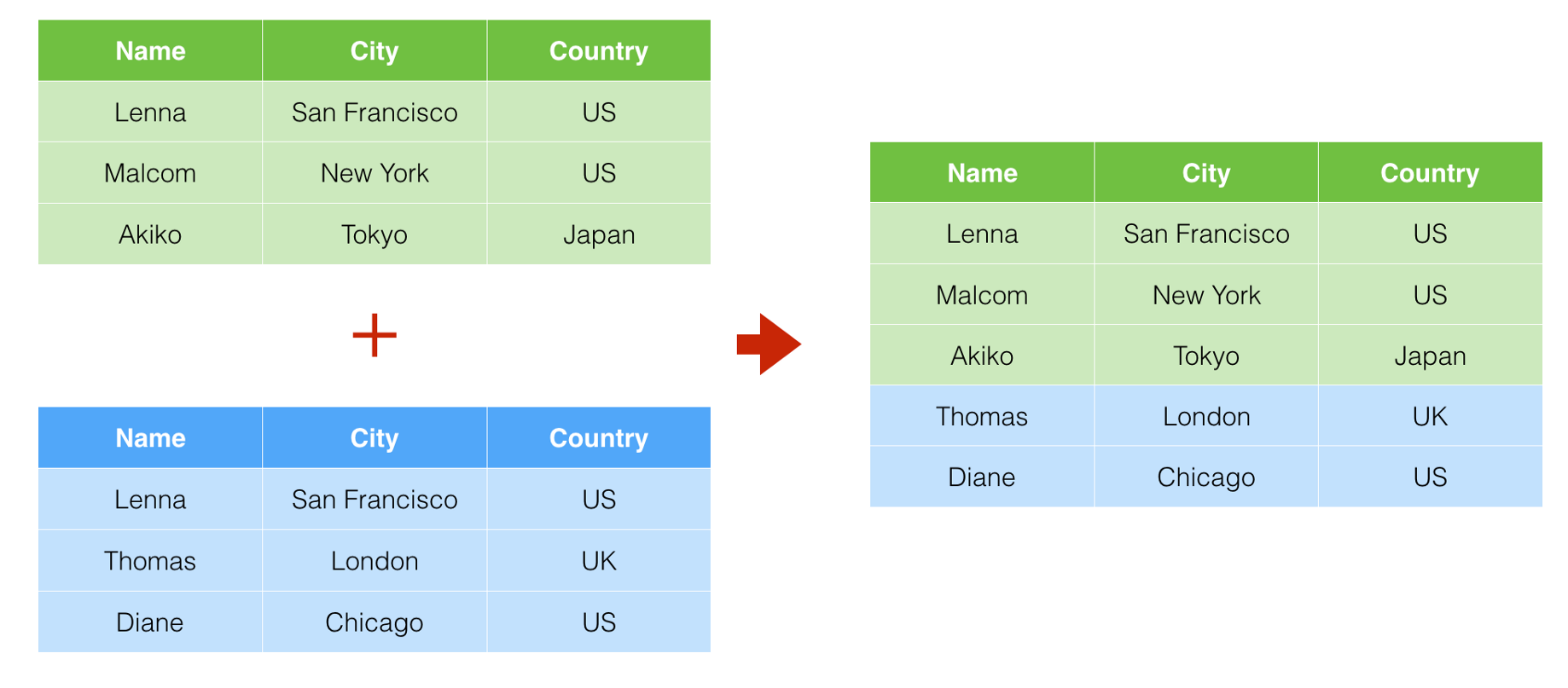
Union will only keep unique values in the resultant dataset on the basis of the selected columns as shown below.
- Let's take two datasets: “Brooklyn Active Sprint Issues” and “Murex Active Sprint Issues”.
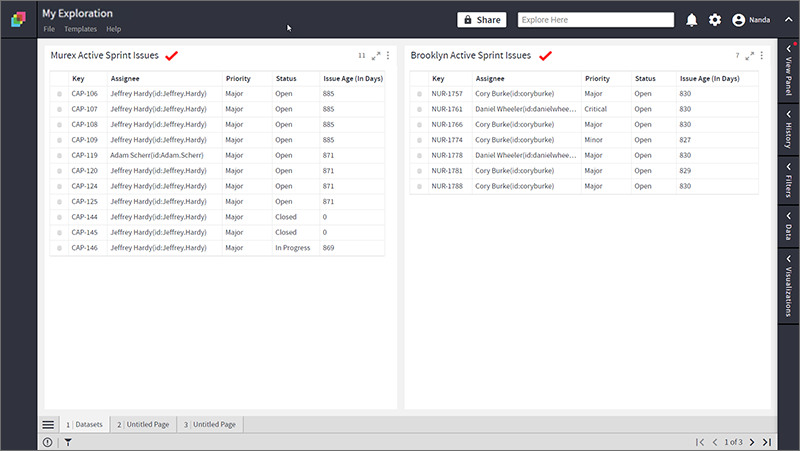
- Select the columns from both the containers using the Ctrl key.
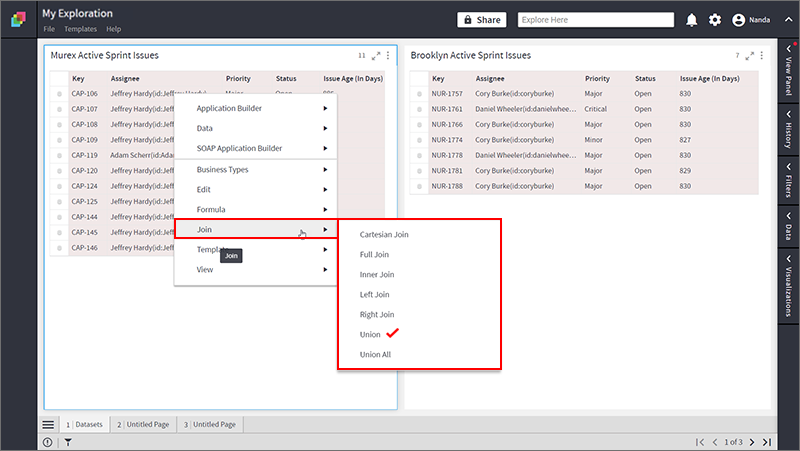
- Right-click and select Join > Union.
- Map the columns to match in both the datasets.
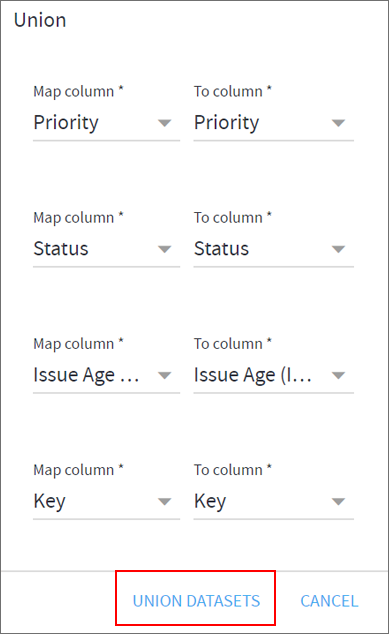
- Click on UNION DATASETS.
- The following figure shows the result of Union.
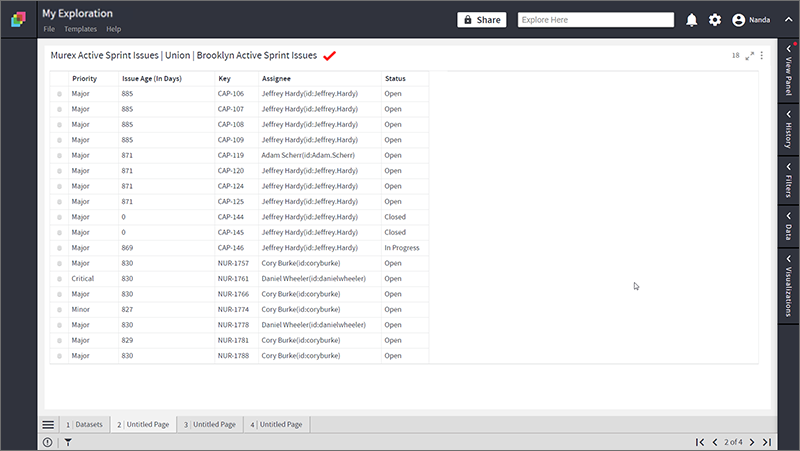
7. Union All
Union All results in all the rows from both the datasets even if they have duplicate data:
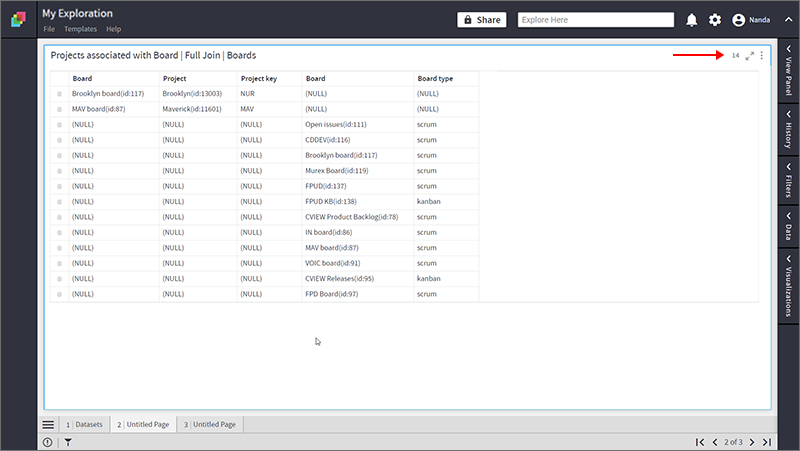
Joins on Containers
You can perform a Join operation without selecting individual columns. You just need to select the containers and right-click on container header as shown below. In this case, the primary key of the two datasets is considered as the Join column. This is useful when you need to join on primary key but it is not shown in the visualization.
The result of Full Join performed on the containers is given below. As primary keys are unique, the result of this operation contains 14 records with other columns as NULL.