Clustering is an unsupervised machine learning algorithm available in Klera to discover themes from unstructured data. Clustering can be done on a column containing text. Clustering is language independent and hence can find themes from multiple languages. Themes discovered from data can be used to group similar records and can be used to find similarities or anomalies in the records.
For example, Clustering helps you analyze unstructured data like Summary of Jira Issues or Commit messages in GitLab or SonarQube.
How to Cluster Data
- Assume that you have fetched issues from Jira.
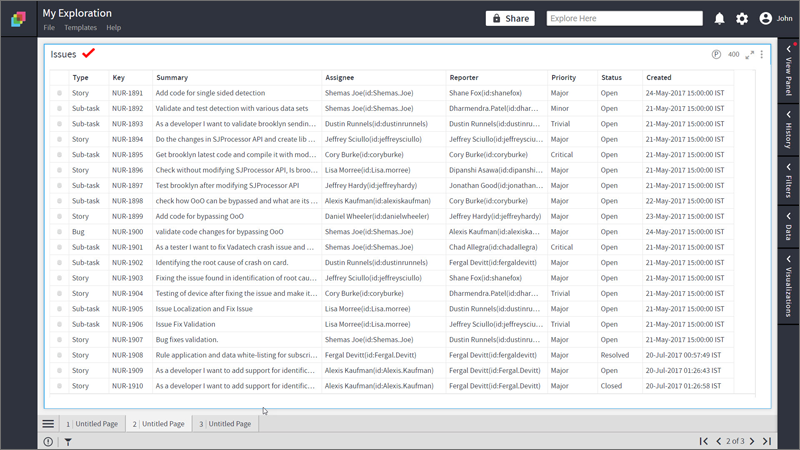
- Open the Data Panel and click on this
icon to select ‘Add Formula’ option as shown below:
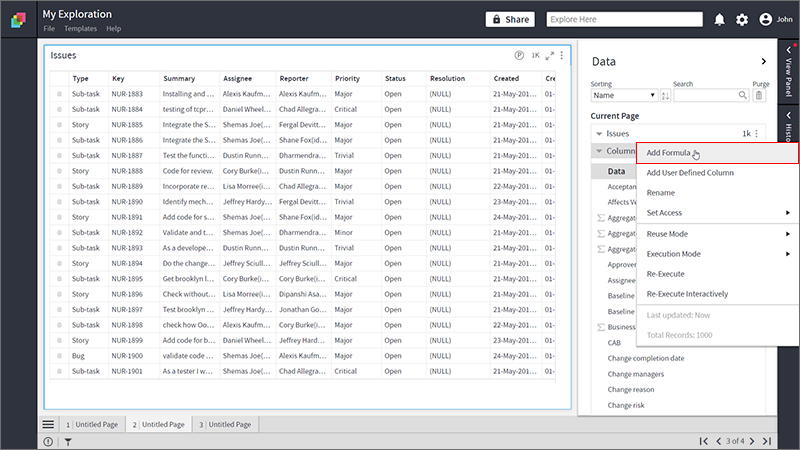
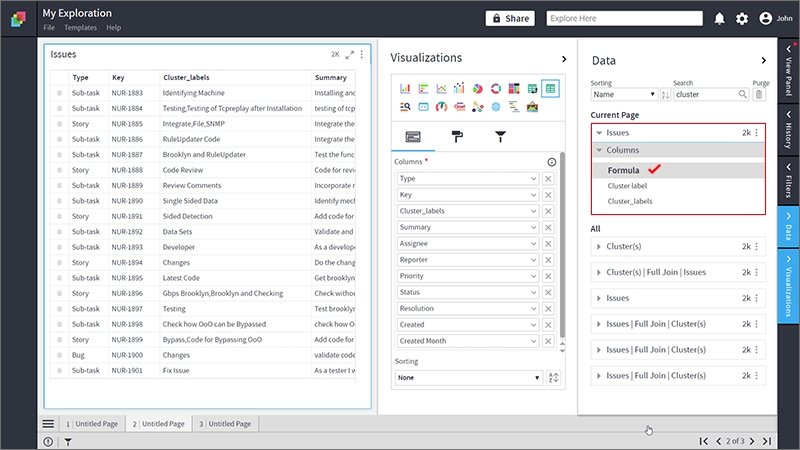
- Type “APPLYCLUSTERING” formula, and provide the name of the column on which you want to identify themes through clustering.
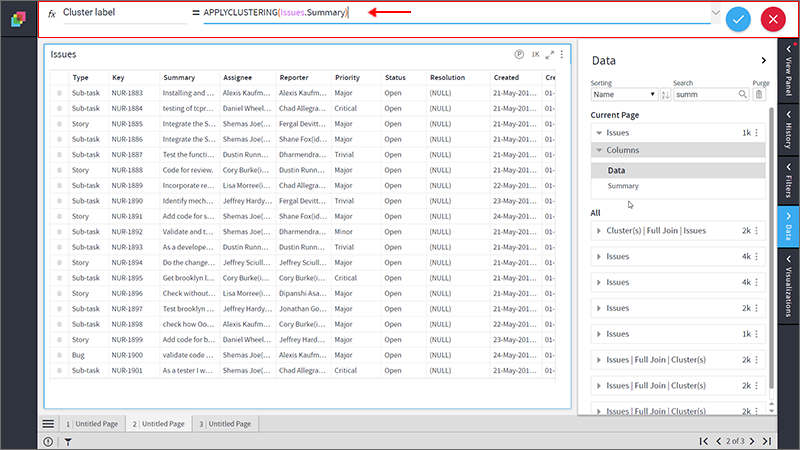
- You can see the newly added column “Cluster Label” under 'Formula' on Data Panel.
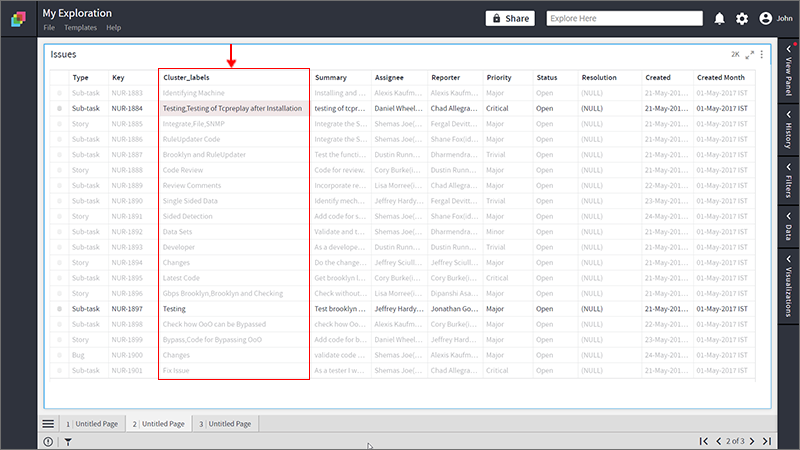
- Select any Cluster Label in the Grid visualization to see related records in the Grid.
Sentiment Analysis
Sentiment Analysis is the analysis of unstructured text data to asses the sentiments expressed in the textual content. Sentiments in unstructured data are rated on a scale of -4 to +4.
The sentiment rating of -4 represents very negative sentiment, 0 being neutral and +4 being very positive. Sentiment analysis is language dependent and Klera currently supports English, most European languages and some Asian languages like Hindi.
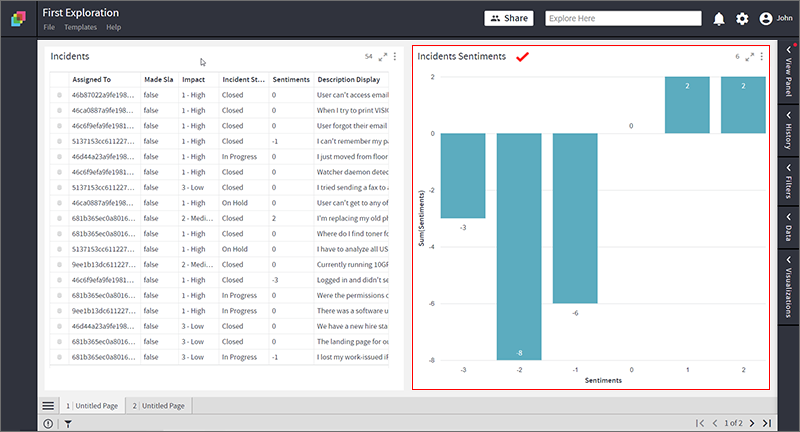
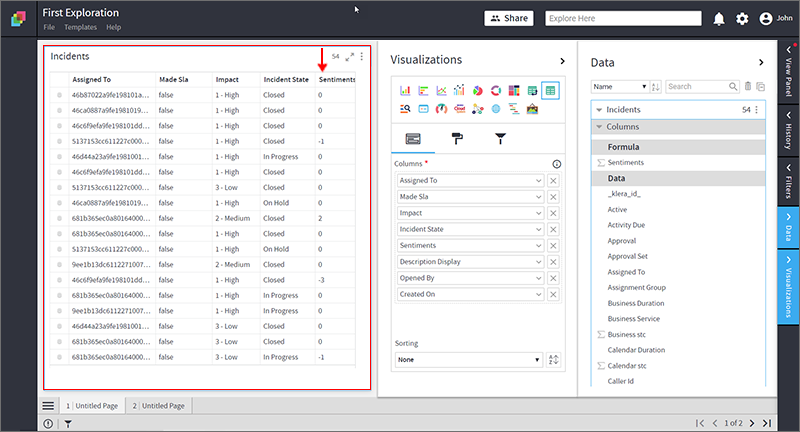
The demonstration of sentiment analysis in this article is based on the incident data from ServiceNow.
- Fetch incidents data from SNOW.
- Open Data Panel, click on this
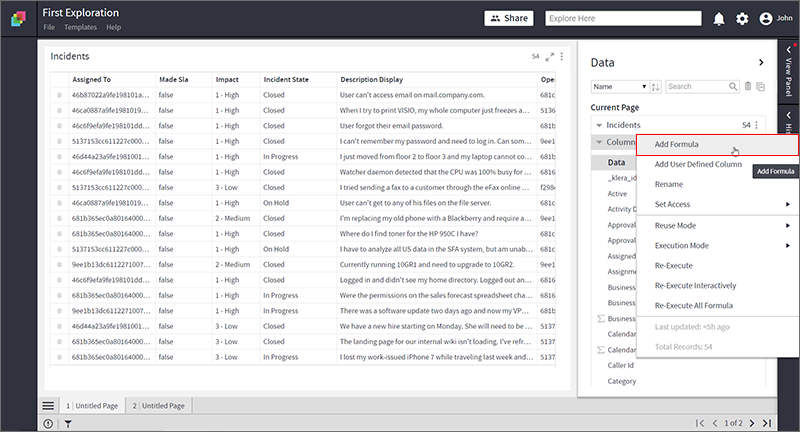
- Apply formula “SENTIMENT” to compute the sentiment score of the description column.

- Add the newly created column to the ‘Incidents’ Grid visualizations. Please notice the sentiment score in the range of -4 to +4.
- You can create various visualizations to gain powerful insights from the sentiment scores. For eg. Bar chart shows positive, negative, and neutral sentiments, intuitively.