Create a Computed Column using Klera’s In-built Functions
Computed Columns
Sometimes, your data may not contain the fields/columns that you need for your analysis. This is when computed columns are required.
For example, your dataset contains release start date and end date. But you need to know how many days it takes for the release. In such scenarios, you can create computed fields or columns in your data.
A computed column is an additional column added to your dataset and can be used for even more advanced calculations and visualizations.
The value of rows of this column is calculated by the system based on a formula. You can create these formulas by using columns (or fields) from one or more datasets.
Klera supports the following arithmetic operators.
|
Arithmetic Operation |
Klera’s Operator |
|
Addition |
+ |
|
Subtraction |
- |
|
Multiplication |
* |
|
Division |
/ |
|
Exponent(Power) |
^ |
Using formulas in Klera is simple and intuitive, much like Excel. Klera also has a rich set of functions that can be used in a formula. Klera has logical, text, date, aggregation and various advanced analytical functions for unstructured text analytics, Machine learning, and custom scripting.
Add a Computed Column
Suppose that you have a sample dataset that contains all the sales data for a chain of stores such as transaction date, product, price, payment type, country etc. This dataset has a column called Price, which is the purchase price to the retailer. To calculate the sales prices with 15% profit for each product, you can create a computed column called 'Selling Price' that contains the following formula:
Selling Price=Price + Price * 0.15
The value of price will be taken from the corresponding row of the ‘Price’ column.
To add this new computed column based on the above formula, follow the steps mentioned below.
Step 1: Open Data Panel.
Under ‘Current Page’, click on the Overflow Menu for your dataset. Select ‘Add Formula’.
Step 2: Write the expression in the formula editor.
In the formula editor, on the left of ‘=’ sign, you can see the default name of the new computed column. You can edit. Type Selling Price.
To the right of ‘=’ sign, you can write your formula. Type the name of the dataset or column in the expression (price- in this example). As you start typing, you will be suggested the available datasets and columns in this format “<Dataset_Name>.<Column_Name>”. Select the appropriate column from the list.
Alternatively, you can also select the column from Data Panel by clicking on the column name.
Complete the expression using mathematical operations.
Step 3: When finished, click on  icon to add a computed column to your dataset.
icon to add a computed column to your dataset.
You might get errors for any incomplete arithmetic expressions. Correct the errors and click icon.
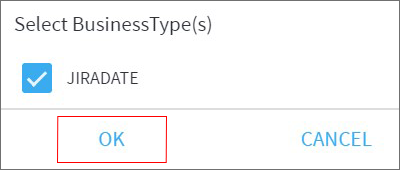
Step 4: Add business type to the newly created column. if business types are defined on the columns present in the formula/function, Klera will provide the suggestions. Select business type(s) from the suggested options and click Ok.
 Note: You can define multiple business types for your column. Note: You can define multiple business types for your column. |
To learn more about business types, refer to section Basic Concepts and Terminology.
The new computed column “Selling Price” is saved to your dataset and can be used to create more calculated columns and visualizations.
Step 5: Add this column to your visualization (Optional Step).
| Note: Not every custom column you create needs to be added to the Visualizations. At times, you might simply be interested in quickly using it in some other calculations. |
To add, open the Visualizations Panel. Drag & drop the newly added column from Data Panel under ‘Columns’ in the Visualizations Panel.

Edit a Computed Column
To edit a computed column, follow the steps given below:
- Open Data panel. For your dataset where the formula is applied, click on
 icon to display all the columns.
icon to display all the columns. - Under Formula, hover over a computed column and click on the
 icon. In the formula editor, edit the formula and select icon.
icon. In the formula editor, edit the formula and select icon.
Remove a computed column
To remove a computed column, follow the steps given below:
1. Open Data panel.
For your dataset where the formula is applied, click on ![]() icon to display all the columns.
icon to display all the columns.
2. Under Formula, hover over a computed column to be deleted. Click on the Overflow Menu  icon and select ‘Delete Column’.
icon and select ‘Delete Column’.
3. Click ‘Yes’ to confirm the removal of the column.
4. If the deleted column was added to your visualization then you need to reconfigure the visualization. Open the Visualizations Panel and remove the column from the view as shown in the following figure.
The column will be successfully removed from the dataset and visualizations.

Klera In-built Functions
A Klera in-built functions are off-the-shelf formulas to perform complex calculations with ease. e.g. SUM, MAX, AVERAGE, VLOOKUP, COUNTIF etc.
All in-built functions have a standard syntax as shown below:
<Function Name> ( [Param1], [Param2], ...)
Parameters are inputs provided to the function. Multiple arguments are separated by a comma.
e.g.: AVG(12, 17, 19)
You can use fields of a dataset as arguments as well.
e.g.: AVG(‘SalesJan2019.Selling Price’)
Categories
Klera in-built functions are organized in the following categories:
- Number Functions (ABSOLUTE, ROUND etc.)
- Text Functions (TOKENIZE, TOUPPER, TRIM etc.)
- Aggregate Functions (SUM, AVERAGE, MAX etc.)
- Lookup Functions (VLOOKUP)
- Date & Time Functions (DATEDIFF, DATEADD etc.)
- Logical Functions (AND, OR)
- Type Conversion (TOINT, TODATE etc.)
- Analytical functions (SENTIMENT, APPLYCLSUTERING etc.)
Klera’s complete function list is available here - List of Functions in Klera
Create a Computed Column using Klera’s In-built Functions
Example: Computed Column using Klera’s In-built Function with Single Dataset.
Suppose “Releases” dataset has a Start date and Release date but you need time taken for the release. Use the DATEDIFF function to calculate the difference between two dates.
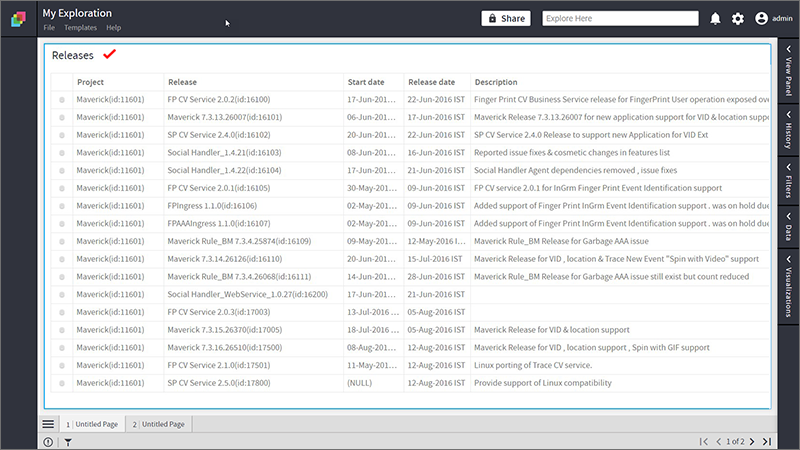
1. Open the formula editor.
2. Type-in few letters of the function name(say date.) Select the function you need, from the drop downs list.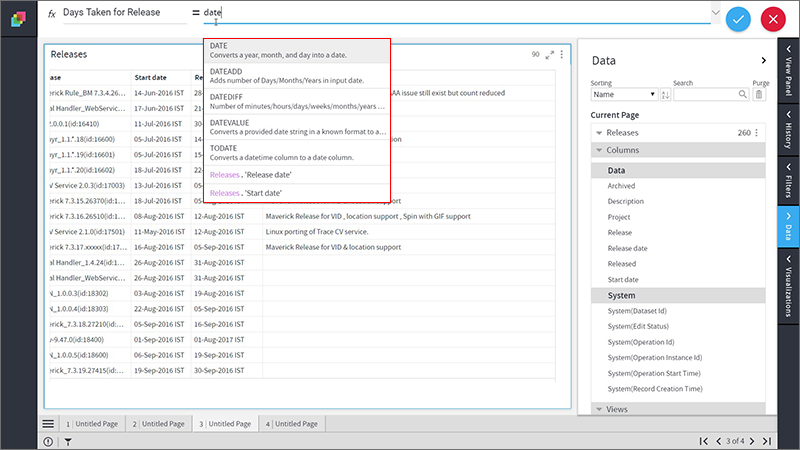
3. A function help box will provide you description, syntax, and a few examples to help you complete the formula.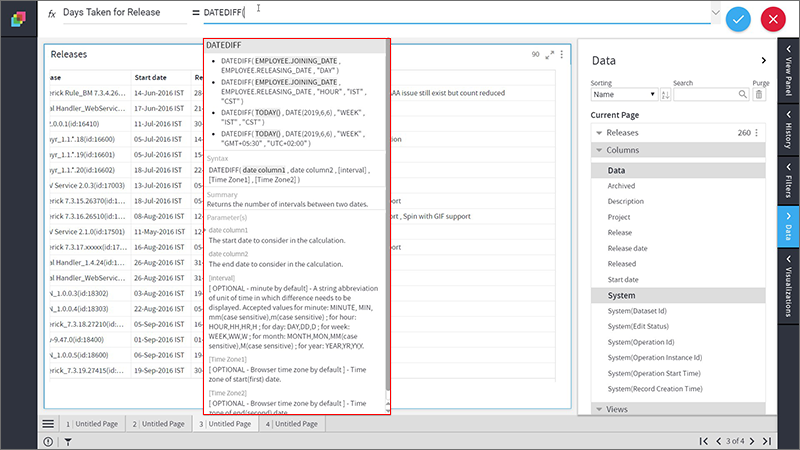
4. Type-in first few letters of the name of the column (to be provided as arguments to the function) and Klera’s autocomplete feature will provide you the list of matching columns and Data Sets. You can choose from the drop-down list.
 Note: You can select columns from multiple datasets on Data Panel. Note: You can select columns from multiple datasets on Data Panel. |
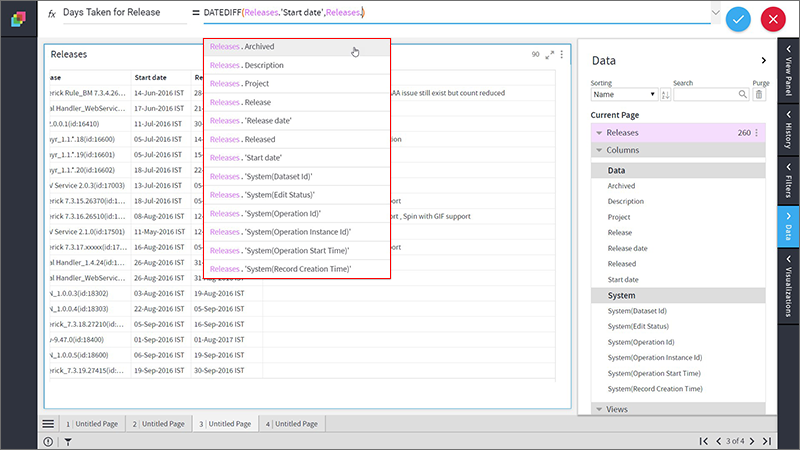
5. Provide all the arguments to complete your formula. In the example, you need to enter the interval as ‘Day’.
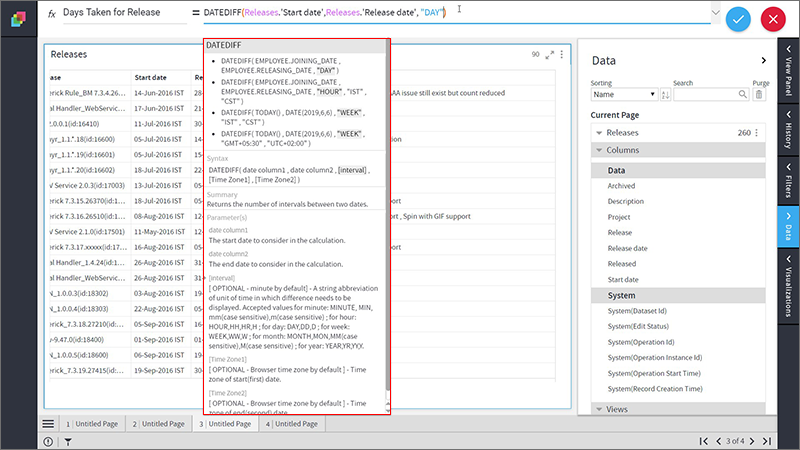
6. When finished, click  icon. Fix the errors (if any) for missing parameters, an incorrect number of required parameters or misplaced closing parenthesis.
icon. Fix the errors (if any) for missing parameters, an incorrect number of required parameters or misplaced closing parenthesis.
7. Add a business type for the newly created column from the suggested options and click OK.
To learn more, refer to section Basic Concepts and Terminology.
List of Functions in Klera
This section lists all the formulas available in Klera.
|
Name |
Examples |
Syntax |
|
ABS |
|
ABS(numeric column)
column: The number for which to return the absolute value. |
|
AND |
|
AND(logical_expression...)
logical_expression: An expression or reference to a column containing an expression that represents some logical value, i.e. TRUE or FALSE. |
|
APPLYCLUSTERING
Returns cluster labels formed on the input string column |
|
APPLYCLUSTERING(String Column, null, null, null, null, null, null, null)
String Column: The input column to be used. It must be a STRING type.
Cluster Count: The number of clusters discovered in each clustering pass. The higher the value of this parameter, the larger the total number of clusters. Default value is '25'
Maximum Document Coverage Target: The percentage of input documents to be put in clusters. Determines the percentage of documents the clustering engine should assign to clusters.The default value is 0.75
Minimum Word Document Frequency: Words with document frequency larger than maximum word document frequency will be ignored. The default value is 0.9
Minimum Cluster Count: The minimum number of clusters count allowed. The default value is 2
Single Word Label Weight: Determines how willing the clustering engine will be to select single words as cluster labels. The higher value of this parameter, the more clusters described with single-word labels will be produced. The default value is 1.5
null: null
null: null |
|
AVERAGEIF
Returns the average of a column, filtered by the criteria. |
|
AVERAGEIF(range, criteria, [average_range])
range: Column range to use to evaluate the criteria.
criteria: The pattern or test to apply to criteria.
[average_range]: Optional. The actual set of cells to average. If omitted, the range is used. |
|
AVERAGEIFS
Returns the average of a range depending on multiple criteria. |
|
AVERAGEIFS(average_range, criteria_range1, critera1, [criteria range2], [critera2]...)
average_range: Column whose average needs to be calculated.
criteria_range1: The column over which to evaluate criteria.
critera1: The pattern or test to apply to criteria.
[criteria range2]: Optional. The additional column over which to evaluate criterion.
[critera2]: Optional. The pattern or test to apply to the associated criteria. |
|
AVG
Returns the average of values from the column(s). |
|
AVG(column1, [column2], ...)
column1: Column from which you want the average.
[column2]: Optional. Additional column from which you want the average. |
|
CHAR
Convert a number into a character according to the universal Unicode table. |
|
CHAR(column)
column: The input column to be used. |
|
CONCAT
Returns the concatenation of multiple values. |
|
CONCAT(Text1, [Text2], ...)
Text1: The first item to join. The item can be a text value, number or a column reference.
[Text2]: Optional. An additional item to join. |
|
COUNT
Returns the count of cells from the column(s). |
|
COUNT(column1, [column2], ...)
column1: Column from which you want to count cells.
[column2]: Optional. An additional column(s) from which you want to count cells. |
|
COUNTIF
Returns a conditional count across a range. |
|
COUNTIF(criteria_range, criteria)
criteria_range: The column over which to evaluate criterion.
criteria: The pattern or test to apply to criteria. |
|
COUNTIFS
Returns a conditional count across a range. |
|
COUNTIFS(criteria_range1, criteria1, [criteria_range2], [criteria2]...)
criteria_range1: The first range over which to evaluate the associated criteria.
criteria1: The pattern or test to apply to criteria.
[criteria_range2]: Optional. Additional column over which to evaluate the associated criteria.
[criteria2]: Optional. The pattern or test to apply to criteria. |
|
DATE
Converts a year, month, and day into a date. |
|
DATE(year, month, day)
year: The year component of the date.
month: The month component of the date.
day: The day component of the date. |
|
DATEADD
Returns a date to which a specified time interval has been added. |
|
DATEADD(date column, number to be added, interval)
date column: The date column to which interval period will be added.
number to be added: Numeric value that will be added to the input date.
interval: A string abbreviation of a unit of time that needs to be added in input date. Accepted values for hour: HOUR, HH, HR, H ; for day: DAY, DD, D ; for week: WEEK, WW, W ; for month: MONTH, MON, MM(case sensitive), M(case sensitive) ; for year: YEAR, YR, YY, Y. |
|
DATEDIFF
Returns the number of intervals between two dates. |
|
DATEDIFF(date column1, date column2, [interval], [Time Zone1], [Time Zone2])
date column1: The start date to consider in the calculation.
date column2: The end date to consider in the calculation.
[interval]: [OPTIONAL - minute by default] - A string abbreviation of a unit of time in which difference needs to be displayed. Accepted values for second: SECOND, SEC, ss, s ; for minute: MINUTE, MIN, mm(case sensitive), m(case sensitive) ; for hour: HOUR, HH, HR, H ; for day: DAY, DD, D ; for week: WEEK, WW, W ; for month: MONTH, MON, MM(case sensitive), M(case sensitive) ; for year: YEAR, YR, YY, Y.
[Time Zone1]: [OPTIONAL - Browser time zone by default] - Time zone of start(first) date.
[Time Zone2]: [OPTIONAL - GMT time zone by default] - Time zone of end(second) date. |
|
DATETIMESTRING
Converts a provided Date, Time, DateTime type value to String. |
|
DATETIMESTRING(Input Column)
Input Column: The DATE, TIME or DATETIME type column or value representing the DATE, TIME or DATETIME value. |
|
DATETIMEVALUE
Converts a provided Date, Time, DateTime, String or Long(datetime in millisecs) input value into Date, Time or DateTime. |
|
DATETIMEVALUE(Input Column, [Input Format], [Output Type], [Time Zone])
Input Column: The Date, Time, DateTime, String or Long value representing Date, Time or Date-Time.
[Input Format]: Parameter2 is not required if parameter1 is Date, Time, DateTime, long or String in the default format("dd-MMM-yyyy HH:mm:ss z") but Parameter2 is required in the custom format in the case where parameter1 is passed as a string, not in the default format. For custom formats accepted letters for Era: G, for Year: y, for Month: M, for Day in year: D, for Day in month: d, for Day name: E, for am/pm marker: a, for Hour in day: H, for Hour in am/pm: h, for Minute in hour: m, for Second in minute: s, for Millisecond Number: S, for Time zone name: z, for Time zone offset: Z, for Time zone: X. All letters are case sensitive. Note: Supports patterns of multiple locale(en_US - English, United States, es - Spanish, fr_CA - French, Canada, fr_FR - French, France, it_IT - Italian, Italy, iw - Hebrew, ja_JP - Japanese, Japan, ko - Korean) and many custom formats.
[Output Type]: [OPTIONAL - return Date-Time value by default] - A string representing result value type. Accepted values for Date result: d, date; for Time result: t, time; for Date-Time result: dt, datetime;(case insensitive).
[Time Zone]: [OPTIONAL - GMT time zone by default] - Time zone to consider. It will be effective only if parameter1 is String and whose input format has no TimeZone mentioned in it.
|
|
DATEVALUE
Converts a provided date string in a known format to a date value |
|
DATEVALUE(date string, [Time Zone])
date string: The string representing the date.
[Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone to consider. |
|
DAY
Returns the day of the month that a specific date falls on, in numeric format. |
|
DAY(date column, [Time Zone])
date column: The date from which to extract the day.
[Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone which needs to be considered to calculate day. |
|
FORMAT
Adds given character to the tokens of a comma-separated string |
|
FORMAT(column, null)
column: Column/Cell or string to format.
character_to_use: the character to add to the beginning and end of the word. SINGLEQUOTE and DOUBLEQUOTE values are supported. |
|
IF
Returns one value if a logical expression is 'TRUE' and another if it is 'FALSE'. |
|
IF(logical_expression, Column_if_true, Column_if_false)
logical_expression: An expression or reference to a Column containing an expression that represents some logical value, i.e. TRUE or FALSE.
Column_if_true: The value the function returns if logical_expression is TRUE.
Column_if_false: The value the function returns if logical_expression is FALSE. |
|
IFALL
Returns 'TRUE' if all of the column value matches given criteria otherwise 'FALSE'. |
|
IFALL(column, criteria, value)
column: The column over which to evaluate criterion.
criteria: The pattern or condition to apply to criteria
value: The value for criteria. |
|
IFANY
Returns 'TRUE' if any of the column value matches given criteria otherwise 'FALSE'. |
|
IFANY(column, criteria, value)
column: The column over which to evaluate criterion.
criteria: The pattern or condition to apply to criteria
value: The value for criteria. |
|
ISNULL
Returns true if the column value is null otherwise false. |
|
ISNULL(column)
column: The column whose value needs to be checked. |
|
ISNUMBER
returns TRUE if this is a number or Column containing a numeric value and FALSE otherwise |
|
ISNUMBER(Column)
Column: The value to be verified as a number. |
|
LARGE
Returns the nth largest element from a data set, where n is user-defined. |
|
LARGE(column, n)
column: The column containing the dataset to consider.
n: The rank from largest to smallest of the element to return.
|
|
LEFT
Returns a substring from the beginning of a specified string. |
|
LEFT(column, [number_of_characters])
column: The column from which the left portion will be returned.
[number_of_characters]: [OPTIONAL - 1 by default] - The number of characters to return from the left side of the string. |
|
LENGTH
returns length of a string |
|
LENGTH(column)
column: The input column to be used. |
|
MAX
Returns the maximum value from column(s). |
|
MAX(column1, [column2], ...)
column1: Column from which you want to find the maximum value.
[column2]: Optional. Additional column from which you want to find the maximum value. |
|
MAXIF
Returns the maximum value from a column, filtered by the criteria. |
|
MAXIF(column, criteria_range, criteria)
column: Column from which the maximum will be determined.
criteria_range: The column over which to evaluate criterion.
criteria: The pattern or test to apply to criteria. |
|
MAXIFS
Returns the maximum value in a column depending on multiple criteria. |
|
MAXIFS(column, criteria_range1, criteria1, [criteria_range2], [criteria2]...)
column: Column from which the maximum will be determined.
criteria_range1: The column over which to evaluate criterion.
criteria1: The pattern or test to apply to criteria.
[criteria_range2]: Optional. The additional column over which to evaluate criterion.
[criteria2]: Optional. The pattern or test to apply to the associated criteria. |
|
MEDIAN
Returns the median value in a numeric dataset. |
|
MEDIAN(column)
column: Numeric column from which the median will be calculated. |
|
MID
Returns a segment of a string. |
|
MID(column, starting_at, extract_length)
column1: The string to extract a segment from.
column2: The index from the left of string from which to begin extracting. The first character in the string has index 1.
column3: The length of the segment to extract. |
|
MIN
Returns the minimum value from column(s). |
|
MIN(column1, [column2], ...)
column1: Column from which you want to find the minimum value.
[column2]: Optional. Additional column from which you want to find the minimum value. |
|
MINIF
Returns the minimum value from a column of a data set, filtered by the criteria. |
|
MINIF(column, criteria_range, criteria)
column: Column from which the minimum will be determined.
criteria_range: The column over which to evaluate criterion.
criteria: The pattern or test to apply to criteria. |
|
MINIFS
Returns the minimum value from a column depending on multiple criteria. |
|
MINIFS(column, criteria_range1, criteria1, [criteria_range2], [criteria2]...)
column: Column from which the minimum will be determined.
criteria_range1: The column over which to evaluate criterion.
criteria1: The pattern or test to apply to criteria.
[criteria_range2]: Optional. The additional column over which to evaluate criterion.
[criteria2]: Optional. The pattern or test to apply to the associated criteria.
|
|
MONTH
Returns the month of the year a specific date falls in, in numeric format. |
|
MONTH(date column, [Time Zone])
date column: The date from which to extract the month.
[Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone which needs to be considered to extract month. |
|
NORMDIST
Returns normal distribution for the specified mean and standard deviation. |
|
NORMDIST(value, mean, standard_deviation, cumulative) value: The value for which you want the distribution.
mean: The arithmetic mean of the distribution.
standard_deviation: The standard deviation of the distribution.
cumulative: It determines the form of the function. If it is TRUE |
|
NOT
Returns the opposite of a logical value - `NOT(TRUE)` returns `FALSE`; `NOT(FALSE)` returns `TRUE`. |
|
NOT(boolean column)
boolean column: The column whose value needs to be inverse. |
|
NOTNULL
Returns true if the column value is not null otherwise false. |
|
NOTNULL(column)
column: The column whose value needs to be checked. |
|
NOW
Returns the current date and time as a date value. |
|
NOW() |
|
NUMBERVALUE
Converts a text string that represents a number to a number value. |
|
NUMBERVALUE(column, Decimal_separator, Group_separator)
column: The column whose text string needs to be converted to number format.If input is boolean then output will be 0/1. If input column is Date/DateTime then output will be number of days since December 30, 1899. If input column is Time then output will be 0.
Decimal_separator: [OPTIONAL Decimal_separator] - The character used to separate the integer and fractional part of the result.
Group_separator: [OPTIONAL Group_separator] - The character used to separate groupings of numbers, such as thousands from hundreds and millions from thousands. |
|
OR
Returns TRUE if any logical expressions is 'TRUE' else return 'FALSE'. |
|
OR(logical_expression)
logical_expression: An expression or reference to a Column containing an expression that represents some logical value, i.e. TRUE or FALSE. |
|
PERCENTILEEXC
Returns the n-th percentile of values in a range, where n is in the range 0..1, exclusive. |
|
PERCENTILEEXC(column, percentile)
column: Numeric column from which the percentile will be calculated.
percentile: The percentile value in the range 0..1, exclusive. |
|
PERCENTILEINC
Returns the n-th percentile of values in a range, where n is in the range 0..1, inclusive. |
|
PERCENTILEINC(column, percentile)
column: Numeric column from which the percentile will be calculated.
percentile: The percentile value in the range 0..1, inclusive. |
|
QUARTILEEXC
Returns the quartile of a data set, exclusive. |
|
QUARTILEEXC(column, quart)
column: Numeric column from which the quartile will be calculated.
quart: Indicates which quart value to return. quart value can be 1, 2, 3. |
|
QUARTILEINC
Returns the quartile of a data set, inclusive. |
|
QUARTILEINC(column, quart)
column: Numeric column from which the quartile will be calculated.
quart: Indicates which quart value to return. quart value can be 0, 1, 2, 3, 4 |
|
RANK
Returns the rank of a specified value in a dataset. |
|
RANK(value, column, [is_ascending])
value: The value whose rank will be determined.
column: Numeric column containing the value to consider.
[is_ascending]: [OPTIONAL - 0 by default] Whether to consider the values in data in descending or ascending order. If this is 0, the greatest value in data will have rank 1; if this is 1, the least value in data will have rank 1. |
|
REGEX
Returns all the matches in a text by applying regex |
|
REGEX(text, regexType, regex)
text: Text column
regexType: Regular Expression Types : NULL, VEHICLENUMBER, HASHTAG, PHONENUMBER, BASE64, EMAIL, URL
regex: [OPTIONAL] Regular Expression to be applied. |
|
REPT
Returns specified text repeated a number of times. |
|
REPT(column, number_of_repetitions)
column: Column/Cell or string to repeat.
number_of_repetitions: The number of times String should appear in the value returned. |
|
RIGHT
Returns a substring from the end of a specified string. |
|
RIGHT(column, [number_of_characters])
column: The column from which the right portion will be returned.
[number_of_characters]: [ OPTIONAL - 1 by default] - The number of characters to return from the right side of the string. |
|
ROUND
Rounds a number to a certain number of decimal places according to standard rules. |
|
ROUND(column1, column2)
column1: The input column to be used. If the input is boolean then the output will be 0/1
column2: The number of decimal places to which to round. |
|
RUNNINGTOTAL
Returns the RunningTotal of values from the column |
|
RUNNINGTOTAL(numeric column, Condition base)
column: The column containing values to perform/calculate running total.
condition: The column whose values will provide the basis to calculate the running total. |
|
SEARCH
Returns the position at which a string is first found within the cell and ignores the capitalization of letters. Returns null if the string is not found. |
|
SEARCH(search_keyword, within_text, [starting_at])
search_keyword: The search string to look for within the input text.
within_text: The input text to be searched for the first occurrence of the search keyword.
[starting_at]: [OPTIONAL - 1 by default] - Position of character within the text from where the search will start. |
|
SENTIMENT
Returns sentiment score for text on a scale of -4 to +4 (Negative to Positive) |
|
SENTIMENT(column)
column: Text column |
|
SMALL
Returns the nth smallest element from a data set, where n is user-defined. |
|
SMALL(column, n)
column: The column containing the dataset to consider.
n: The rank from smallest to largest of the element to return. |
|
SQRT
Returns the SquareRoot of values from the column |
|
SQRT(numeric column)
column: The number of which to return the SqureRoot value. |
|
STDDEV
Returns standard deviation of a numeric dataset. |
|
STDDEV(column)
column: Numeric column from which standard deviation will be calculated. |
|
SUM
Returns the sum of values from the column(s). |
|
SUM(column1, [column2], ...)
column1: Column from which you want the sum.
[column2]: Optional. Additional column from which you want the sum. |
|
SUMIF
Returns the sum of a column, filtered by the criteria. |
|
SUMIF(criteria_range, critera, [sum_range])
criteria_range: The column over which to evaluate criterion.
criteria: The pattern or test to apply to criteria.
[sum_range]: The actual cells to add if you want to add cells other than those specified in the range argument. |
|
SUMIFS
Returns the sum of a column depending on multiple criteria. |
|
SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2], [criteria2]...)
sum_range: Column to use to calculate the sum.
criteria_range1: The column over which to evaluate criterion.
criteria1: The pattern or test to apply to criteria.
[criteria_range2]: Optional. The additional column over which to evaluate criterion.
[criteria2]: Optional. The pattern or test to apply to the associated criteria. |
|
TODATE
Converts a datetime column to a date column. |
|
TODATE(column)
column: The column to be converted to a date. |
|
TODAY
Returns the current date as a date value. |
|
TODAY() |
|
TOINT
Returns integer values of a column. |
|
TOINT(column, data type)
column: The column whose value needs to be converted to an integer value. If input is boolean then the output will be 0/1. If input column is Date/DateTime then output will be the number of days since December 30, 1899. If input column is Time then output will be 0.
data type: [OPTIONAL - long data type will get used by default] -The data type of resultant column. |
|
TOKENIZE
Divides text around a specified character or string, and puts each fragment into a comma seprated values. |
|
TOKENIZE(column, delimiter, [split_by_each], stopwords, [include_system_stopwords])
column: Column whose values need to be tokenized.
delimiter: [OPTIONAL - space is used to split by default] -The character or characters to use to split text
[split_by_each]: [OPTIONAL - TRUE by default] - Whether or not to divide text around each character contained in the delimiter.
stopwords: [OPTIONAL] - words list which will be ignored.
[include_system_stopwords]: [OPTIONAL - TRUE by default] - Whether or not to include system-defined stopwords list which will be ignored. |
|
TOLATITUDE
Converts the Longitude String values into klera compatible format |
|
TOLATITUDE(Latitude)
Latitude: Latitude column |
|
TOLONGITUDE
Converts the Longitude String values into klera compatible format |
|
TOLONGITUDE(Longitude)
Longitude: Longitude column |
|
TOLOWER
Converts a specified string to lowercase. |
|
TOLOWER(column)
column: The column to convert to lowercase. |
|
TOSTRING
Returns string values of a column. |
|
TOSTRING(column)
column: The column whose value needs to be converted to the string value. |
|
TOUPPER
Converts a specified string to uppercase. |
|
TOUPPER(column)
column: The column to convert to uppercase. |
|
TRIM
Removes leading and trailing spaces in a specified string. |
|
TRIM(column)
column: The column containing a string to be trimmed. |
|
VALUE
Converts a text string that represents a number to a number. |
|
VALUE(column)
column: The column whose text string needs to be converted to number format. If input is boolean then output will be 0/1. If input column is Date/DateTime then output will be number of days since December 30, 1899. If input column is Time then output will be 0. |
|
VAR
Returns the variance of a numeric dataset. |
|
VAR(column)
column: Numeric column from which the variance will be calculated. |
|
VLOOKUP
Vertical lookup. Searches down the search column for a search key and returns the value of a specified output column from the matched row. |
|
VLOOKUP(search_key, search column, output column)
search_key: The value to search for. Value can be a data set column or any single value For example "John", 1002.
search column: The data set column to consider for the search. It should be a column only. The first value in the search column is searched for the key specified in search_key.
output column: The data set column to be considered to return the value, where the corresponding value of search column matches the search_key. search column and output column should belong to the same data set. |
|
VLOOKUPALL
Vertical lookup all. Searches down the search column for a search key and returns all the matched values of a specified output column |
|
VLOOKUPALL(search_key, search column, output column)
search_key: The value to search for. Value can be a data set column or any single value. For example "John", 1002.
search column: The data set column to be considered for the search. It should be a column only. All values in the search column are searched for the key specified in search_key.
output column: The data set column to be considered to return the value, where the corresponding value of search column matches the search_key. search column and output column should belong to the same data set. |
|
WEEKDAY
Returns a number representing the day of the week of the date provided. |
|
WEEKDAY(date column, [type], [Time Zone])
date column: The date for which to determine the day of the week.
[type]: [OPTIONAL - 1 by default] - A number indicating which numbering system to use to represent weekdays. By default, counts starting with Sunday = 1. If type is 1, days are counted from Sunday and the value of Sunday is 1, therefore the value of Saturday is 7. If type is 2, days are counted from Monday and the value of Monday is 1, therefore the value of Sunday is 7. If type is 3, days are counted from Monday and the value of Monday is 0, therefore the value of Sunday is [Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone which needs to be considered to calculate the day of the week. |
|
WEEKNUM
Returns a number representing the week of the year where the provided date falls. |
|
WEEKNUM(date column, [type], [Time Zone])
[type]: [OPTIONAL - 1 by default] - A number representing the day that a week starts on as well as the system used for determining the first week of the year (1=Sunday, 2=Monday).
[Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone which needs to be considered to calculate week number.
date column: The date for which to determine the week number.
|
|
YEAR
Returns the year specified by a given date. |
|
YEAR(date column, [Time Zone])
date column: The date from which to calculate the year.
[Time Zone]: [OPTIONAL - Browser time zone by default] - Time zone which needs to be considered to extract year. |